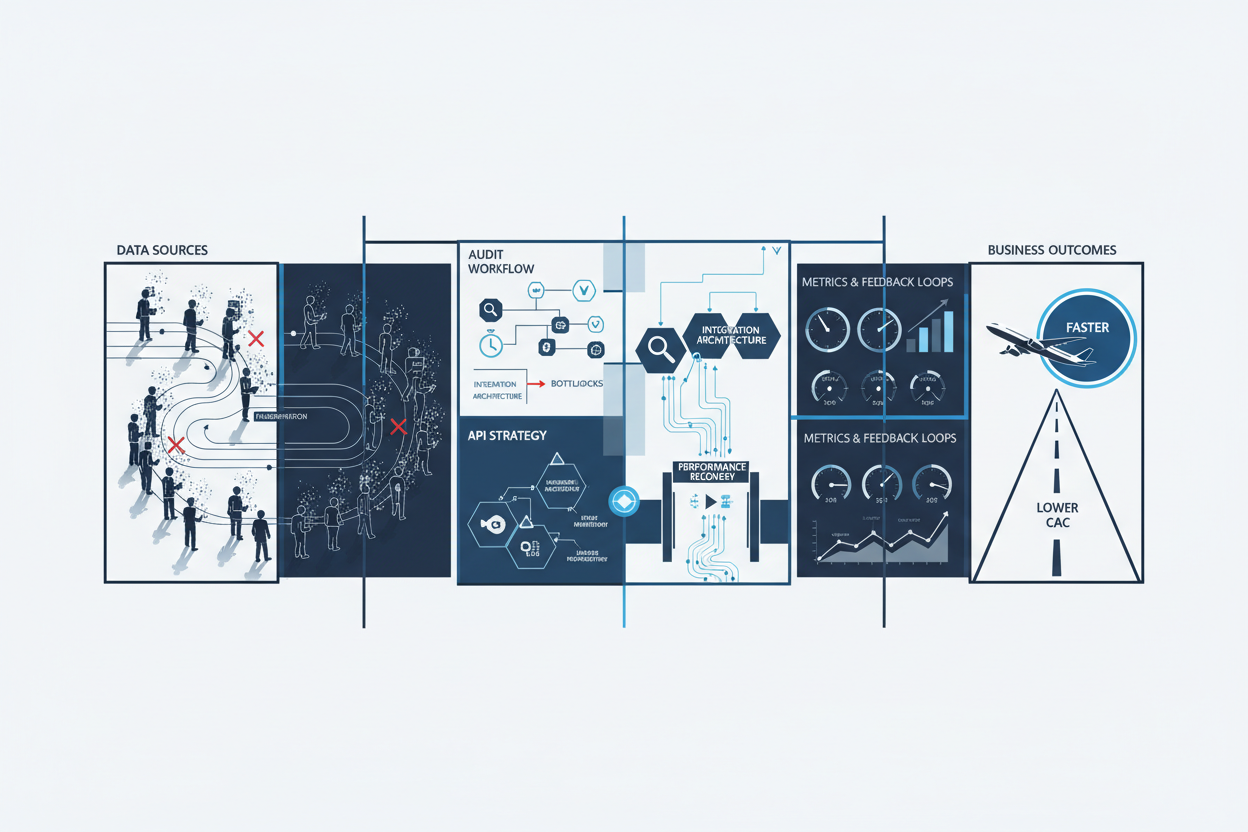
Operations-heavy businesses frequently grapple with slow website audits and performance degradation, symptoms that often trace back to fragmented data sources and suboptimal integration architectures. These challenges directly impact developer experience (DX) and engineering productivity, creating a vicious cycle where slow feedback loops delay issue resolution and increase time-to-market.
The first step in the audit workflow is to establish a comprehensive diagnostic framework that captures both qualitative and quantitative indicators of DX and productivity. This includes:
- Latency and throughput metrics across API endpoints and integration layers, revealing bottlenecks in data flow.
- Developer feedback loops through surveys and interviews to identify pain points in tooling, onboarding, and debugging.
- Codebase and deployment analysis to detect architectural anti-patterns such as tight coupling, redundant data transformations, and inconsistent API contracts.
- Audit trail completeness to ensure traceability and compliance without sacrificing performance.
By correlating these data points, engineering leaders can pinpoint root causes of slow audits and performance issues, such as excessive API chattiness, lack of caching strategies, or fragmented monitoring systems.
Priorities: Aligning Developer Experience Improvements with Business Outcomes
Once the audit reveals critical bottlenecks, prioritization must balance immediate performance gains with sustainable developer experience enhancements. The overarching goal is to lower customer acquisition cost by enabling faster, reliable launches without quality loss.
Key priorities include:
- Streamlining integration architecture: Consolidate fragmented data sources into unified API gateways or service meshes to reduce latency and simplify data reconciliation.
- Standardizing API contracts and versioning: Enforce backward compatibility and clear deprecation policies to minimize integration friction and reduce debugging overhead.
- Improving observability: Implement end-to-end tracing and centralized logging to accelerate incident diagnosis and reduce mean time to recovery (MTTR).
- Enhancing developer tooling: Provide self-service environments, automated testing pipelines, and real-time feedback mechanisms to boost productivity and morale.
These priorities align tightly with integration architecture and API strategy, ensuring that technical decisions directly support operational excellence and faster time-to-market.
Quick Wins: Tactical Remediations to Accelerate Performance Recovery
In the context of slow website audits and fragmented data, quick wins focus on low-effort, high-impact changes that unblock engineering teams and improve system responsiveness.
Examples include:
- Implementing API response caching: Introduce caching layers at strategic points to reduce redundant data fetches and lower backend load.
- Consolidating monitoring dashboards: Merge disparate observability tools into a unified interface to provide developers with a single source of truth.
- Automating audit data aggregation: Use scheduled jobs or event-driven pipelines to pre-compile audit reports, reducing runtime overhead during website audits.
- Refactoring critical API endpoints: Optimize or rewrite high-latency endpoints identified during the audit to improve overall system responsiveness.
These tactical steps can be implemented within weeks and yield measurable improvements in both developer experience and engineering throughput.
Deep Fixes: Architectural and Process-Level Enhancements for Long-Term Productivity
While quick wins address immediate pain points, deep fixes require strategic investments in architecture and process redesign to sustain productivity gains and support scaling.
Key deep fixes include:
1. Integration Architecture Rationalization
Fragmented data sources often stem from organic growth without a unified integration strategy. A deliberate rationalization involves:
- Defining bounded contexts and data ownership to reduce cross-team dependencies.
- Implementing API gateways or service meshes to centralize routing, authentication, and rate limiting.
- Adopting event-driven patterns where appropriate to decouple services and enable asynchronous data flows.
This approach reduces complexity, improves data consistency, and accelerates incident resolution.
2. API Strategy and Governance
Establishing a robust API strategy is critical for maintaining integration quality and developer productivity. This includes:
- Defining clear API lifecycle policies, including versioning, deprecation, and backward compatibility.
- Enforcing contract-first development with automated validation and testing.
- Implementing API documentation standards and developer portals to facilitate onboarding and reduce support load.
Governance mechanisms ensure that APIs evolve predictably, minimizing integration breakages and accelerating feature delivery.
3. Developer Experience Engineering
Improving DX requires investing in tooling and processes that reduce cognitive load and friction. Recommended actions include:
- Providing sandbox environments with realistic data for safe experimentation.
- Integrating continuous integration/continuous deployment (CI/CD) pipelines with fast feedback loops.
- Embedding observability hooks and debugging aids directly into developer workflows.
These enhancements empower engineers to identify and resolve issues proactively, shortening development cycles.
Quality Control: Acceptance Criteria and Continuous Improvement
To ensure that remediation efforts translate into measurable outcomes, define acceptance criteria aligned with business goals and technical standards. Key metrics include:
- Audit duration reduction: Target a specific percentage decrease in website audit times, reflecting improved data integration and processing efficiency.
- API latency and error rates: Establish thresholds for acceptable response times and failure rates, monitored continuously.
- Developer satisfaction scores: Use periodic surveys to track improvements in DX and identify residual pain points.
- Deployment frequency and lead time: Measure engineering throughput improvements enabled by enhanced tooling and processes.
Continuous monitoring against these criteria supports iterative refinement and risk mitigation.
Practical Implementation: A Mini-Case on Integration Architecture Optimization
Consider an operations-heavy B2B platform suffering from slow website audits due to multiple CRM and ERP systems feeding inconsistent data through disparate APIs. The engineering team initiated an audit revealing excessive API calls, redundant data transformations, and fragmented monitoring.
Following the remediation roadmap, they prioritized consolidating data sources via an API gateway that standardized contracts and caching policies. They introduced contract-first API development with automated validation and integrated observability dashboards accessible to developers.
Within three months, audit times decreased by 40%, API latency improved by 30%, and developer satisfaction scores rose significantly. These gains enabled faster feature releases and reduced acquisition costs, directly impacting business outcomes.
Conclusion and Next Steps
Improving developer experience and engineering productivity in operations-heavy businesses facing slow website audits requires a disciplined audit workflow, clear prioritization, tactical quick wins, and strategic deep fixes focused on integration architecture and API strategy. Defining acceptance criteria and embedding continuous quality control ensures sustained performance recovery and faster launches without quality loss.
For organizations seeking expert guidance on implementing these principles, our integration architecture and API strategy services provide tailored solutions that align technical vision with measurable business outcomes.
Explore related insights in our Technical SEO Audit and Integration Plan for Operations-Heavy Businesses, B2B SaaS and Internal Tooling SEO-Safe Redesign and Migration Implementation Plan, and Solution Architecture for Growing Content-Driven Commercial Websites to deepen your understanding of integration-driven engineering productivity improvements.
Operationalizing the Acceptance Checklist: Concrete Steps and Checklists
To translate the acceptance checklist into actionable workflows, teams should adopt a phased approach that balances immediate remediation with sustainable improvements. Below is a practical sequence to operationalize the checklist effectively:
- Baseline Assessment: Conduct a comprehensive audit to quantify current bottlenecks in website audit duration, API performance, and developer satisfaction. Use automated tools to gather metrics and qualitative surveys to capture developer pain points.
- Prioritization Workshop: Engage cross-functional stakeholders—including engineering, operations, and product management—to align on business impact and technical feasibility. Prioritize quick wins that unblock critical workflows and deep fixes that address systemic issues.
- Implementation Roadmap: Develop a detailed plan with milestones, resource allocation, and risk mitigation strategies. Include checkpoints for quality control and acceptance criteria validation.
- Incremental Delivery: Adopt an iterative rollout model where quick wins are deployed first to demonstrate value and build momentum. Follow with deep fixes implemented in phases to minimize disruption.
- Continuous Monitoring and Feedback: Establish dashboards that track key acceptance metrics in real time. Schedule regular retrospectives to incorporate developer feedback and adjust priorities accordingly.
This structured approach ensures that remediation efforts remain focused, measurable, and adaptable to evolving business needs.
Anti-Patterns to Avoid During Remediation
While pursuing improvements, teams should be vigilant against common anti-patterns that can undermine progress:
- Overloading APIs with Responsibilities: Avoid designing monolithic APIs that attempt to serve multiple unrelated functions, which complicates maintenance and slows response times.
- Ignoring Backward Compatibility: Breaking existing API contracts without proper versioning or deprecation plans can disrupt dependent systems and erode developer trust.
- Neglecting Observability: Failing to embed monitoring and logging from the outset limits visibility into performance regressions and complicates troubleshooting.
- Skipping Developer Feedback Loops: Implementing changes without continuous input from developers risks introducing friction and missing critical usability issues.
- Rushing Deep Fixes Without Adequate Testing: Large-scale architectural changes require thorough validation to prevent regressions and ensure stability.
Recognizing and mitigating these anti-patterns early helps maintain momentum and safeguards quality.
Implementation Example: Streamlining API Versioning and Deprecation
In one operations-heavy enterprise, the engineering team faced frequent integration failures due to inconsistent API versioning practices. Legacy clients often broke when new API versions were introduced without clear deprecation timelines or backward compatibility guarantees.
To address this, the team established a formal API lifecycle policy that mandated:
- Semantic versioning with clear major, minor, and patch distinctions.
- Deprecation notices communicated via developer portals and automated alerts.
- Grace periods of at least six months before retiring older versions.
- Automated contract testing integrated into CI pipelines to validate backward compatibility.
This policy was codified in governance documentation and enforced through tooling that blocked merges violating versioning rules. As a result, integration stability improved markedly, reducing support tickets by 25% and accelerating onboarding of new clients.
Checklist for Developer Experience Engineering Enhancements
To systematically improve developer experience, teams can use the following checklist as a guide:
- Sandbox Environment: Is there a dedicated, isolated environment with realistic test data for developers to experiment safely?
- CI/CD Integration: Are build and deployment pipelines automated with fast feedback loops on code quality and test results?
- Observability: Are logs, metrics, and traces accessible and integrated into developer tools for quick diagnosis?
- Documentation: Is API documentation comprehensive, up-to-date, and easily searchable?
- Onboarding: Are there clear guides and tutorials to accelerate new developer ramp-up?
- Feedback Channels: Are mechanisms in place for developers to report issues and suggest improvements?
Regularly auditing against this checklist helps maintain a high-quality developer experience that supports productivity and innovation.
Risk Management and Trade-Offs in Performance Recovery
While accelerating performance recovery is critical, it is important to balance speed with stability and maintainability. Key risks and trade-offs include:
- Technical Debt Accumulation: Quick fixes that bypass architectural principles may introduce debt that complicates future enhancements.
- Resource Allocation: Focusing heavily on deep fixes can delay immediate business value, while overemphasizing quick wins may leave systemic issues unresolved.
- Change Fatigue: Rapid, frequent changes can overwhelm teams and users, leading to resistance or errors.
- Complexity vs. Flexibility: Introducing sophisticated integration patterns (e.g., event-driven architectures) increases complexity but can improve scalability and decoupling.
Effective governance, clear communication, and incremental delivery mitigate these risks while maximizing benefits.
Rollout Scenarios: Phased vs. Big Bang
Choosing the right rollout strategy depends on organizational context and risk tolerance. Two common scenarios are:
Phased Rollout: Deploy changes incrementally to subsets of users or systems, allowing for controlled validation and rollback if issues arise. This approach reduces risk and enables learning but may prolong the full benefits realization.
Big Bang Rollout: Implement all changes simultaneously across the environment. This can accelerate impact but carries higher risk of widespread disruption if problems occur.
For operations-heavy businesses with complex dependencies, phased rollouts are generally recommended to safeguard continuity and enable iterative improvement.
Embedding Continuous Improvement in Engineering Culture
Long-term productivity gains require embedding continuous improvement into the engineering culture. Practical steps include:
- Establishing regular retrospectives focused on developer experience and system performance.
- Incentivizing knowledge sharing and cross-team collaboration to spread best practices.
- Allocating dedicated time for technical debt reduction and tooling enhancements.
- Leveraging metrics and feedback loops to identify emerging bottlenecks proactively.
By fostering a culture that values quality, transparency, and learning, organizations can sustain momentum and adapt to evolving challenges.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.
Web application architecture audit
Audit architecture, security and performance with a clear improvement plan.
Bitrix or website integration with marketplace API
I integrate marketplace APIs with your website or Bitrix so synchronization stops relying on manual workarounds.