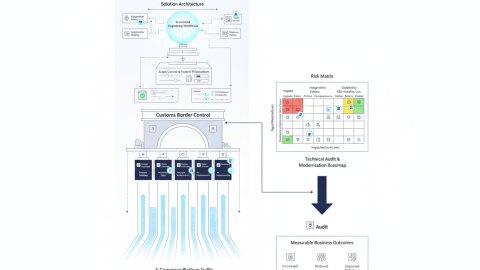
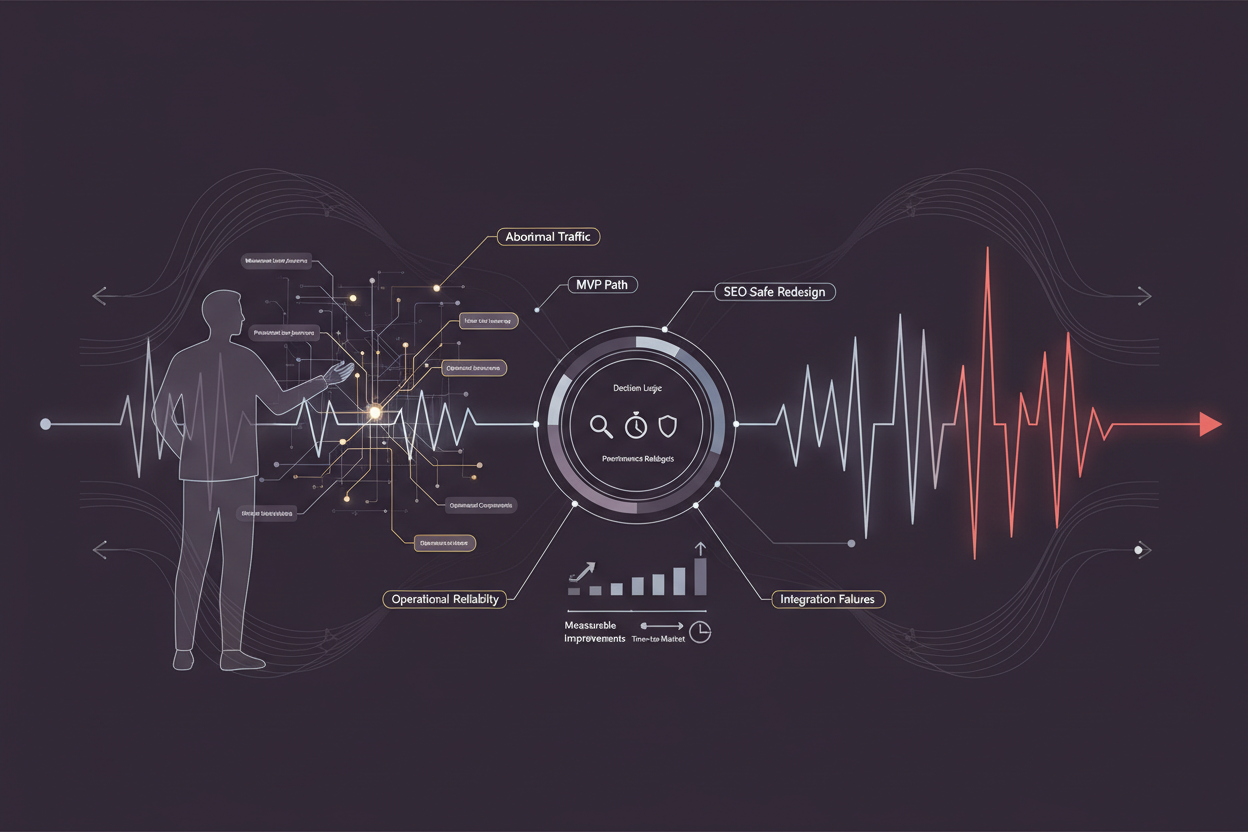
In operations-heavy businesses, the MVP (Minimum Viable Product) delivery path for web performance engineering and rendering strategy must be tightly scoped to balance rapid time-to-market with sustainable operational reliability. The core challenge lies in architecting a solution that supports SEO-safe redesign and migration without incurring regressions or incidents that could disrupt critical business workflows.
The first step is to delineate the MVP scope with clear boundaries: identify the essential user journeys, prioritize pages and components with the highest operational impact, and define performance budgets aligned with SEO and user experience goals. This prioritization ensures that engineering efforts focus on the most impactful rendering optimizations and infrastructure improvements.
For example, in a logistics-heavy B2B portal, the MVP might focus on optimizing the dashboard and order tracking pages, which are accessed frequently and have complex data integrations. Rendering strategies here must minimize time-to-interactive and avoid layout shifts that degrade perceived performance and SEO rankings.
Decision logic in this phase involves evaluating existing bottlenecks through profiling and audit tools, then selecting rendering approaches—such as server-side rendering (SSR), static site generation (SSG), or hybrid incremental static regeneration—that best fit the operational constraints and content update frequency. The MVP path should also incorporate fallback mechanisms to gracefully handle integration failures or slow backend responses, reducing incident risk during rollout.
Concrete implementation steps include:
- Conducting a baseline performance audit focusing on key SEO metrics like Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS).
- Mapping critical user flows and backend dependencies to identify rendering choke points.
- Defining performance budgets and acceptance criteria aligned with SEO-safe redesign principles.
- Selecting rendering strategies that balance dynamic content needs with caching and CDN capabilities.
- Establishing rollback and monitoring plans to detect regressions early during MVP rollout.
This approach ensures that the MVP delivers measurable improvements in page load speed and SEO compliance while maintaining operational stability.
Scope Boundaries: Engineering Constraints and Integration Complexity
Operations-heavy businesses often contend with complex integration landscapes, including legacy ERP, CRM, and custom middleware systems. These integrations impose strict constraints on web performance engineering and rendering strategies, as backend response times and data consistency directly affect frontend rendering quality and SEO outcomes.
Establishing clear scope boundaries involves identifying which integrations are in scope for the MVP and which require deferred optimization. This prioritization is critical to avoid scope creep and ensure that the MVP remains deliverable within tight budget and deadline constraints.
For instance, if a marketing portal integrates with multiple lead-source systems, the MVP might initially focus on optimizing rendering for the primary lead capture pages, deferring secondary integrations to later phases. This decision reduces complexity and risk, allowing the team to concentrate on core performance improvements.
From an infrastructure engineering perspective, scope boundaries also dictate the choice of caching layers, CDN configurations, and edge computing capabilities. These components must be aligned with the rendering strategy to maximize cache hit ratios and minimize backend load, directly impacting time-to-market and incident rates.
Key considerations include:
- Defining integration SLAs and their impact on rendering time budgets.
- Segmenting content by update frequency to apply appropriate rendering modes (static vs. dynamic).
- Implementing API gateway throttling and fallback strategies to protect frontend rendering pipelines.
- Ensuring SEO-safe URL structures and metadata management within integration constraints.
- Planning for incremental rollout of integration optimizations post-MVP.
By rigorously defining scope boundaries, engineering teams can reduce incident risk and maintain predictable delivery timelines, a critical factor for operations-heavy businesses under pressure.
Success Metrics: Measuring Impact and Ensuring SEO-Safe Outcomes
Success in web performance engineering and rendering strategy is measured not only by raw speed improvements but also by SEO compliance, operational reliability, and user experience consistency. Establishing a robust set of success metrics is essential for acceptance testing and ongoing monitoring.
Key performance indicators (KPIs) should include:
- SEO Metrics: Core Web Vitals (LCP, FID, CLS), crawlability, indexability, and structured data validation.
- Performance Metrics: Time to First Byte (TTFB), Time to Interactive (TTI), total blocking time, and resource load efficiency.
- Operational Metrics: Incident frequency related to rendering failures, rollback rates during deployment, and backend API error rates impacting frontend rendering.
- User Experience Metrics: Bounce rates, session duration, and conversion funnel drop-offs correlated with page performance.
Implementing a monitoring framework that integrates synthetic testing, real user monitoring (RUM), and SEO auditing tools enables continuous validation against these metrics. This framework supports early detection of regressions and facilitates data-driven remediation.
For example, a controlled rollout of the MVP rendering strategy can leverage feature flags and phased deployment to monitor impact on SEO rankings and user engagement. If metrics degrade beyond defined thresholds, automated rollback or targeted fixes can be triggered, minimizing business disruption.
Checklist for success metric implementation:
- Define baseline metrics from pre-MVP audits.
- Set quantitative acceptance thresholds aligned with SEO and UX goals.
- Integrate monitoring dashboards with alerting for key KPIs.
- Establish incident response protocols tied to metric deviations.
- Plan for periodic metric reviews and iterative optimization cycles.
This disciplined approach ensures that performance engineering efforts translate into tangible business outcomes, reducing incidents and improving time-to-market.
Production Evolution: Controlled Rollout and Continuous Improvement Roadmap
After MVP acceptance, the production environment becomes the proving ground for the rendering strategy and performance engineering investments. Operations-heavy businesses must adopt a controlled rollout approach combined with a continuous improvement roadmap to manage risk and maximize ROI.
Controlled rollout involves incremental exposure of the new rendering pipeline to increasing user segments, supported by robust feature flagging and canary deployment mechanisms. This approach limits blast radius in case of unforeseen regressions and provides real-world data to refine performance tuning.
Infrastructure engineering best practices recommend layering rollout with automated quality gates based on the success metrics defined earlier. These gates act as decision points to proceed, pause, or rollback deployments, ensuring operational stability.
Continuous improvement post-MVP focuses on:
- Expanding rendering optimizations to secondary pages and integrations.
- Refining caching strategies and CDN configurations based on observed traffic patterns.
- Enhancing backend API performance to reduce frontend rendering latency.
- Incorporating advanced rendering techniques such as edge-side rendering or partial hydration where applicable.
- Regularly updating SEO metadata and structured data to maintain search engine compliance.
As a practical mini-case, a B2B logistics platform implemented a phased rollout of SSR combined with CDN edge caching. Initial MVP focused on the order tracking page, achieving a 30% reduction in LCP and a 15% increase in user session duration. Subsequent phases extended optimizations to the dashboard and reporting modules, guided by continuous monitoring and incident triage protocols.
This evolution strategy balances innovation with operational risk management, a necessity for operations-heavy businesses with tight budgets and deadlines.
Anti-Patterns to Avoid
During redesign and migration, several anti-patterns can undermine performance and SEO objectives:
- Overloading MVP scope: Attempting to optimize all pages and integrations simultaneously leads to delays and increased incident risk.
- Ignoring backend latency: Frontend rendering optimizations without addressing slow API responses result in limited gains.
- Skipping monitoring setup: Lack of real-time metrics impedes early detection of regressions.
- Neglecting SEO-safe URL and metadata management: Causes ranking drops and indexing issues post-migration.
- Deploying without rollback plans: Increases downtime and recovery time during incidents.
Practical Implementation Checklist
- Baseline audit of performance and SEO metrics.
- Define MVP scope with prioritized pages and integrations.
- Choose rendering strategy aligned with content dynamics and infrastructure capabilities.
- Implement caching and CDN configurations supporting the rendering approach.
- Set up monitoring dashboards and alerting for key KPIs.
- Plan controlled rollout with feature flags and quality gates.
- Establish rollback and incident response protocols.
- Iterate post-MVP with continuous improvement cycles.
For teams seeking expert guidance on MVP definition, controlled rollout, and performance engineering under operational constraints, our services provide tailored audit and implementation roadmaps. Explore case studies in our projects and deepen your understanding with insights from our release engineering runbook and observability-driven resilience architecture articles.
By adhering to this acceptance checklist and remediation roadmap, operations-heavy businesses can confidently execute SEO-safe redesigns and migrations that deliver measurable performance gains, reduce incident rates, and accelerate time-to-market within tight budget and deadline constraints.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.
Support-to-sales handoff workflow
I configure the support-to-sales handoff so valuable requests do not get lost between systems and teams.
Calculator or configurator on Bitrix
I build a calculator or configurator that helps produce qualified leads, not just interface clicks.