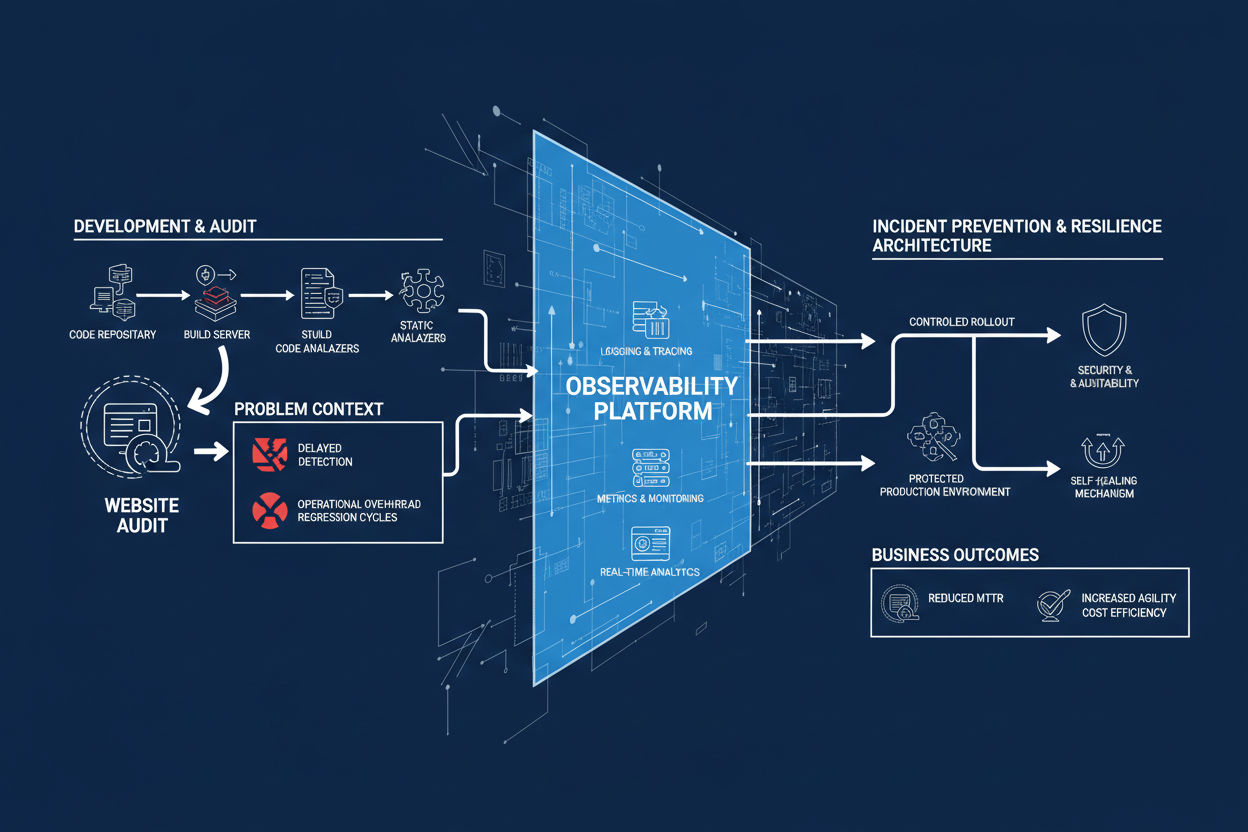
Product teams shipping Minimum Viable Products (MVPs) often face a paradox: the need for rapid iteration clashes with the realities of slow website audits and performance recovery cycles. These delays not only extend time-to-market but also increase the risk of undetected regressions and incidents post-release. In regulated or security-sensitive environments, auditability requirements further constrain the pace and flexibility of deployments.
From a business architecture perspective, this scenario demands a robust incident prevention and resilience strategy that integrates observability deeply into the product lifecycle. Observability here is not a mere monitoring add-on but a foundational capability enabling proactive detection, root cause analysis, and controlled rollout decisions.
Symptoms: Operational Overhead and Incident Recurrence Patterns
Teams grappling with slow audits and performance recovery often report recurring symptoms that signal architectural and process deficiencies:
- Delayed incident detection: Critical performance degradations or security anomalies surface only after customer impact.
- High operational overhead: Manual triage and firefighting consume engineering bandwidth, detracting from feature development.
- Regression cycles: Repeated performance regressions due to insufficient pre-release visibility.
- Audit bottlenecks: Compliance checks slow down release cadence, increasing risk exposure windows.
These symptoms collectively erode business agility and inflate costs, undermining the MVP’s strategic value.
Root Causes: Architectural and Process Gaps Undermining Resilience
Understanding the root causes behind these symptoms is essential for targeted remediation. Key factors include:
- Fragmented observability: Disparate metrics, logs, and traces without unified correlation hinder timely incident detection.
- Insufficient performance baselining: Lack of historical performance benchmarks impedes anomaly detection during audits.
- Opaque release processes: Limited visibility into deployment stages and quality gates increases regression risk.
- Reactive incident management: Absence of automated alerting and incident prevention controls leads to firefighting rather than prevention.
- Security and audit constraints: Strict compliance requirements restrict rapid experimentation and rollback agility.
These gaps create a vicious cycle where slow audits delay feedback loops, and limited observability obscures early warning signals.
Solution: An Observability-Centric Architecture Blueprint for Incident Prevention and Resilience
Addressing these root causes requires a deliberate architecture that embeds observability as a strategic asset. The blueprint involves several interlocking components:
1. Unified Observability Platform with Contextual Correlation
Implement an integrated observability platform that consolidates metrics, logs, and distributed traces into a single pane of glass. This enables cross-layer correlation, such as linking frontend latency spikes with backend service errors or database slowdowns. Contextual correlation accelerates root cause analysis and reduces mean time to detection (MTTD).
2. Performance Baselining and Anomaly Detection
Establish performance baselines derived from historical audit data and production telemetry. Use these baselines to define dynamic thresholds and anomaly detection rules that trigger early warnings before SLA breaches occur. This proactive approach shifts the team from reactive firefighting to preventive maintenance.
3. Release Pipeline Instrumentation and Quality Gates
Embed observability checks into the CI/CD pipeline, including automated performance regression tests and security compliance scans. Define quality gates that must be passed before promoting builds to production. This controlled rollout mechanism reduces the risk of regressions and audit failures.
4. Incident Prevention Controls and Automated Remediation
Leverage automated alerting based on observability signals to trigger incident prevention workflows. For example, auto-scaling policies can be activated when resource exhaustion is detected, or circuit breakers can isolate failing components to maintain overall system resilience. Automated remediation reduces operational overhead and improves system uptime.
5. Audit-Ready Observability Data Retention and Reporting
Design observability data retention policies aligned with audit requirements, ensuring traceability and compliance without compromising performance. Implement reporting dashboards tailored for audit stakeholders, providing transparent evidence of system health and incident management.
Rollout Plan: Phased Implementation for MVP Product Teams
Given the constraints of MVP delivery, the rollout of this observability-driven architecture should be incremental and aligned with business priorities:
Phase 1: Baseline Assessment and Quick Wins
- Conduct an observability maturity assessment focusing on current tooling, data silos, and incident patterns.
- Implement centralized logging and basic metric collection to unify visibility.
- Define initial performance baselines using existing audit data.
Phase 2: Pipeline Integration and Quality Gates
- Integrate observability checks into CI/CD pipelines, including automated regression and security tests.
- Establish quality gates and rollback policies to enforce release discipline.
- Train teams on interpreting observability data for release decisions.
Phase 3: Advanced Incident Prevention and Compliance Reporting
- Deploy automated alerting and remediation workflows based on anomaly detection.
- Implement audit-ready data retention and reporting dashboards.
- Continuously refine baselines and alert thresholds based on operational feedback.
This phased approach balances speed with control, enabling MVP teams to reduce operational overhead while satisfying security and auditability constraints.
Checklist: Ensuring Observability-Driven Incident Prevention and Resilience
Before and during rollout, product teams should verify the following to maximize impact:
- Unified observability data: Are metrics, logs, and traces correlated and accessible in a single platform?
- Performance baselines: Are historical audit and production data used to define dynamic thresholds?
- Pipeline quality gates: Are automated performance and security checks integrated into CI/CD workflows?
- Automated alerting: Are anomaly detection alerts configured to trigger incident prevention actions?
- Compliance alignment: Is observability data retention and reporting designed to meet audit requirements?
- Team enablement: Are engineering and operations teams trained to leverage observability insights effectively?
Practical Mini-Case: Accelerating Incident Recovery in a SaaS MVP
A SaaS product team delivering an MVP faced frequent performance regressions detected only after customer complaints, leading to costly firefighting and delayed audits. By adopting the observability blueprint outlined above, they unified telemetry data and established performance baselines aligned with audit cycles. Integrating quality gates into their CI/CD pipeline prevented regressions from reaching production. Automated alerts and remediation workflows reduced incident resolution time by 60%, while audit-ready dashboards streamlined compliance reporting. This transformation enabled the team to accelerate release cadence without compromising reliability or security.
Conclusion: Observability as a Strategic Lever for MVP Product Teams
In the complex landscape of MVP delivery constrained by slow website audits and performance recovery, observability emerges as a critical business architecture enabler. By embedding unified telemetry, performance baselining, pipeline quality gates, and automated incident prevention controls, product teams can reduce operational overhead, prevent incidents, and meet stringent audit requirements.
For teams seeking to implement this architecture blueprint and achieve measurable operational excellence, exploring tailored MVP definition and controlled rollout services can provide structured guidance and execution support. Discover more about these offerings at our services page.
For further insights on related operational playbooks and engineering workflows, consider our detailed articles on workflow automation for marketing and lead generation, technical SEO for scalable content systems, and platform migration and replatforming risk control.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.


