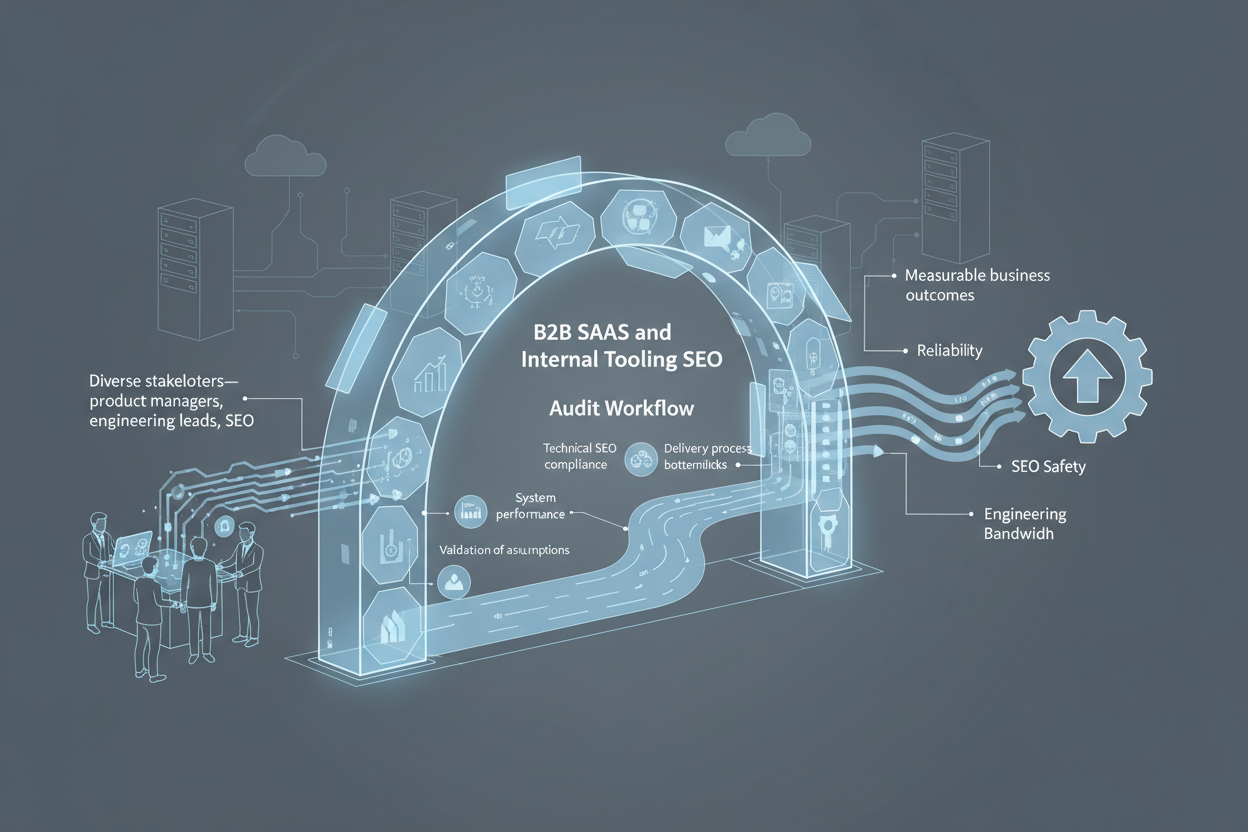
Before embarking on a redesign or migration of B2B SaaS products and internal tooling, especially with SEO safety as a constraint, a comprehensive audit workflow is indispensable. This audit serves as the foundation for aligning diverse stakeholders—product managers, engineering leads, SEO specialists, and business owners—around a shared understanding of current system health, risks, and opportunities.
The audit should cover multiple dimensions: technical SEO compliance, system performance metrics, integration points, and delivery process bottlenecks. For example, identifying legacy API endpoints that cause latency spikes or SEO-unfriendly URL structures that degrade organic visibility. This diagnostic phase must be data-driven, leveraging logs, performance dashboards, and SEO crawl reports.
Crucially, the audit workflow must be transparent and iterative. Early findings should be communicated in stakeholder workshops to validate assumptions and surface hidden constraints. This collaborative approach reduces misalignment risks and sets the stage for prioritizing remediation efforts based on business impact and engineering effort.
For a detailed methodology on audit workflows in similar contexts, see our Technical SEO Audit and Integration Plan for Operations-Heavy Businesses.
Priorities: Balancing Reliability, SEO Safety, and Engineering Bandwidth
With audit insights in hand, the next step is to define clear priorities that reflect the dual goals of increasing delivery reliability and maintaining SEO integrity, all within limited engineering bandwidth. This triad often presents trade-offs that require deliberate decision-making.
For instance, refactoring a monolithic internal tool to microservices might improve scalability but risks introducing SEO crawl disruptions if URL patterns or page rendering change. Conversely, deferring SEO-related fixes to focus on backend stability could lead to organic traffic drops, undermining business KPIs.
To navigate these trade-offs, prioritize initiatives that deliver measurable KPIs such as reduced page load times, improved crawl budget efficiency, or decreased incident rates. Use a weighted scoring model that factors in business impact, technical complexity, and cross-team dependencies. This approach ensures that limited engineering resources focus on high-leverage tasks.
Engage stakeholders early to validate these priorities, ensuring that product owners understand the technical rationale and SEO teams appreciate the operational constraints. This alignment fosters shared ownership of outcomes and smoother execution.
Quick Wins: Tactical Improvements to Boost Confidence and Momentum
Implementing quick wins early in the delivery cycle builds momentum and demonstrates tangible progress to stakeholders. These are typically low-effort, high-impact fixes identified during the audit phase.
Examples include optimizing server response headers for SEO compliance, fixing broken internal links, or implementing caching strategies to reduce latency spikes. Such changes often require minimal code refactoring but yield immediate improvements in reliability and SEO metrics.
Quick wins also serve as practical test cases for the delivery pipeline and quality gates. For example, integrating automated SEO checks into the CI/CD process can catch regressions early, reducing rework and increasing deployment confidence.
Documenting these wins and their impact in regular stakeholder updates reinforces alignment and justifies continued investment. For practical guidance on integrating performance engineering into delivery pipelines, refer to our Web Performance Engineering and Rendering Strategy.
Deep Fixes: Addressing Core Architectural and Process Challenges
After quick wins, focus shifts to deep fixes that tackle systemic issues uncovered during the audit. These often involve architectural refactoring, process redesign, or integration overhaul—tasks that require careful planning and cross-team coordination.
For example, migrating legacy internal tooling to a modular, API-driven architecture can improve scalability and observability but demands a phased rollout to avoid SEO disruptions. Implementing feature flags and canary releases helps mitigate risks by enabling incremental validation.
Another deep fix might be redesigning the deployment pipeline to embed SEO validation steps, such as automated sitemap generation and metadata verification. This integration ensures that SEO considerations are baked into the delivery process rather than treated as afterthoughts.
Trade-offs here include balancing the time and resource investment against the long-term reliability and SEO benefits. Prioritize deep fixes that unlock future agility and reduce technical debt, even if initial costs are higher.
For a comprehensive approach to release engineering and operational reliability in similar contexts, explore our Release Engineering and Operational Reliability Runbook.
Quality Control: Ensuring Sustainable Delivery and Measurable Outcomes
Quality control mechanisms are the linchpin for sustaining improvements and ensuring that delivery remains predictable and aligned with SEO goals. This involves establishing robust testing, monitoring, and feedback loops.
Implement automated regression tests that cover SEO-critical elements such as canonical tags, structured data, and page load performance. Combine these with synthetic monitoring to detect SEO-impacting outages or slowdowns before they affect users or search engines.
Observability dashboards should integrate SEO metrics alongside system health indicators, enabling cross-functional teams to correlate incidents with SEO performance drops. Incident triage processes must include SEO impact assessments to prioritize fixes effectively.
Regular post-release reviews with stakeholders help validate that KPIs are met and identify areas for continuous improvement. This disciplined approach transforms delivery from a reactive firefighting mode to a proactive, data-driven practice.
To deepen your understanding of observability-driven incident prevention and resilience, review our Observability-Driven Incident Prevention and Resilience Architecture.
Practical Mini-Case: Aligning Stakeholders in a B2B SaaS Migration
A mid-sized B2B SaaS provider faced challenges migrating their internal tooling to a new platform while preserving SEO rankings. Initial audits revealed fragmented stakeholder priorities: product teams prioritized feature velocity, SEO specialists feared traffic loss, and engineering was constrained by bandwidth.
By instituting a cross-functional steering committee and adopting the audit-prioritize-quick wins-deep fixes-quality control framework, the team aligned on a phased migration plan. Early quick wins included fixing URL redirects and optimizing server response times, which improved SEO metrics and built trust.
Deep fixes involved modularizing the backend and embedding SEO checks in the CI/CD pipeline. Quality control was reinforced with automated SEO regression tests and real-time monitoring dashboards. The result was a 30% reduction in incident rates and stable organic traffic throughout the migration.
Conclusion and Next Steps
Delivering B2B SaaS products and internal tooling with SEO-safe redesign and migration requires a disciplined, stakeholder-aligned implementation plan. By following a structured audit workflow, prioritizing based on measurable KPIs, executing quick wins, addressing deep architectural fixes, and embedding quality control, organizations can increase reliability and predictability despite limited engineering bandwidth.
For organizations seeking expert guidance on performance engineering and delivery optimization, our services provide tailored solutions that ensure measurable business outcomes. Engage with us to develop a roadmap that balances technical rigor with practical constraints, driving sustainable growth and operational excellence.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.