| Aspect | Legacy Systems | Cloud SaaS Multi-Tenant |
|---|---|---|
| Backlog Visibility | Limited, often siloed logs and manual tracking causing delayed incident detection. | Centralized monitoring with SLA-driven dashboards, easier backlog quantification and trend analysis. |
| Ownership Model | Centralized teams managing monolithic event processing, resulting in bottlenecks. | Distributed ownership across tenants and microservices, requiring clear runbooks and coordinated incident response. |
| Recovery Method | Batch reprocessing or manual replays with downtime risk and customer disruption. | Incremental replay with backpressure controls and phased rollout minimizing impact on SLAs and end-users. |
| Tooling & Automation | Partial automation requiring manual overrides; limited test coverage. | Automated incident detection, rollback mechanisms, and continuous testing embedded in deployment pipelines. |
| SLA Impact | High risk of SLA violations and data inconsistency during event replay. | Predictable delivery managed via quality gates and staged rollout phases, reducing SLA breaches. |
Tradeoffs in Designing Event Queue Backlog Recovery for SaaS Migration
When migrating from legacy platforms to cloud-native SaaS with multi-tenancy, fintech organizations face critical trade-offs:
- Speed versus Stability: Accelerating backlog replay reduces delay but risks overwhelming downstream systems and violating SLAs. A staged, incremental replay prioritizes stability but extends recovery.
- Centralized versus Distributed Runbook Ownership: Centralized operations improve coordination but can bottleneck incident response; distributed ownership empowers teams but risks divergent practices without clear enforcement mechanisms.
- Automated Rollout versus Manual Control: Fully automated rollback and retry pipelines reduce human error but require sophisticated test coverage and safety checks; manual methods maintain control but slow down remediation.
- Tenant Isolation versus Shared Resource Efficiency: Strict tenant-level isolation during event replay increases operational complexity but protects customer SLAs, whereas shared resource strategies optimize cost but risk tenant cross-impact.
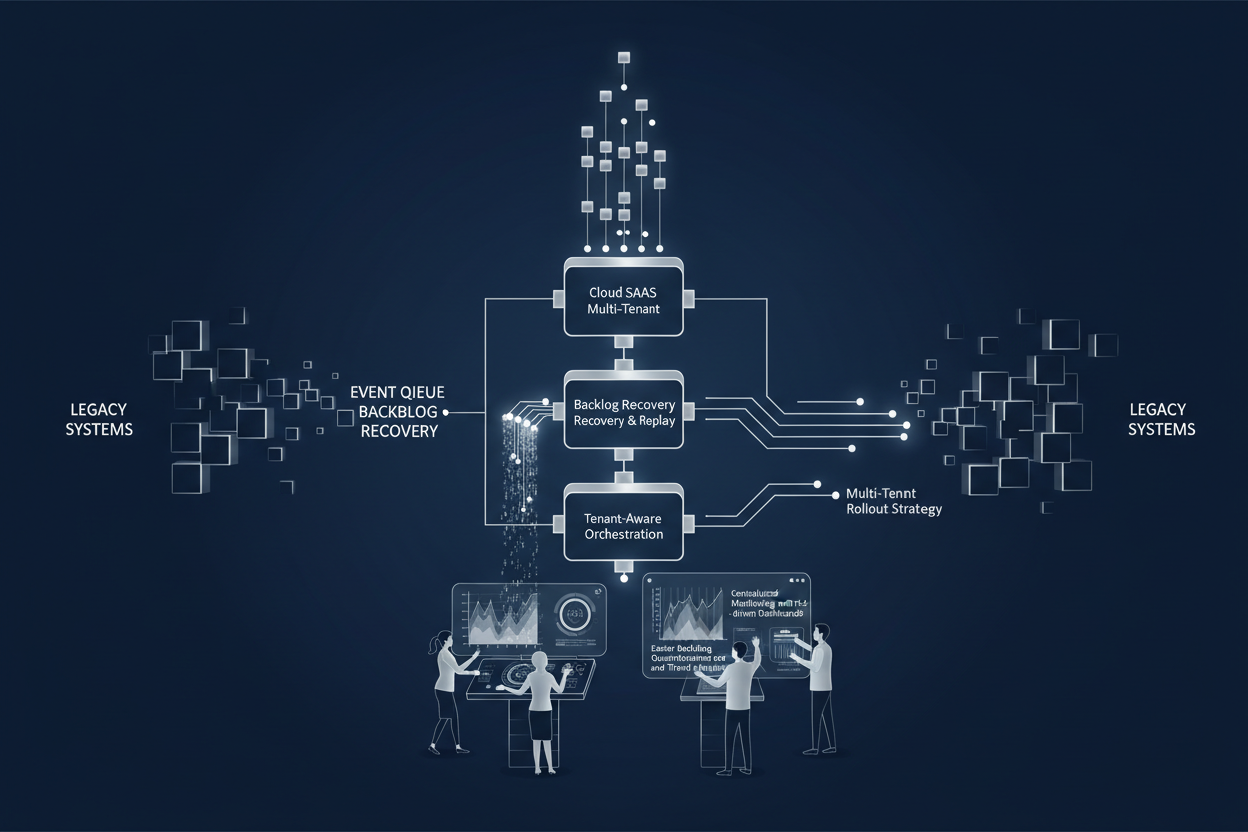
Reference Architecture for Event Queue Backlog Recovery in SaaS Multi-Tenant Migration
This architecture targets fintech SaaS platforms migrating legacy event queues with backlogs due to incident-related processing delays.
- Event Bus Layer: Adopt a scalable message broker supporting tenant-aware queues or topics with priority-based processing capabilities.
- Backlog Detection Service: Continuous monitoring component analyzing event queue depth, latency metrics, and anomaly patterns per tenant.
- Replay Orchestrator: Manages staged backlog replays via quality gates, rate throttling, and tenant isolation policies. Can pause, resume, or rollback replays based on SLA alerts.
- Distributed Ownership Interfaces: Role-based access for tenant teams to run targeted replays or view monitoring dashboards aiding decentralized accountability.
- Central Runbook Repository: Version-controlled documentation with incident scenarios, recovery steps, and escalation paths accessible to all owners.
- Deployment Pipeline Integration: Automated unit, integration, and chaos tests validate replay logic and safeguard production event consistency.
Typical Data Flow:
Legacy backlog metrics --> Backlog Detection Service --> Replay Orchestrator --> Tenant Queues --> Processing Microservices --> SLA Monitoring Dashboards
Code Snippet: Event Replay Orchestrator Control Logic (Pseudocode)
class ReplayOrchestrator:
def __init__(self, backlog_threshold, max_replay_rate, tenant_policies, sla_monitor):
self.backlog_threshold = backlog_threshold
self.max_replay_rate = max_replay_rate
self.tenant_policies = tenant_policies
self.sla_monitor = sla_monitor
def initiate_replay(self, tenant_id, backlog_size):
if backlog_size < self.backlog_threshold:
return "Replay not needed"
rate_limit = self.tenant_policies.get_replay_rate(tenant_id) or self.max_replay_rate
self.sla_monitor.register_observer(tenant_id, self.sla_callback)
self._replay_events(tenant_id, backlog_size, rate_limit)
return "Replay started"
def _replay_events(self, tenant_id, backlog_size, rate_limit):
events_replayed = 0
while events_replayed < backlog_size:
if self.sla_monitor.check_sla_violation(tenant_id):
self.pause_replay(tenant_id)
break
batch = self.fetch_events_for_replay(tenant_id, batch_size=rate_limit)
self.process_batch(batch)
events_replayed += len(batch)
def pause_replay(self, tenant_id):
# Implement pause and alert procedures
pass
def sla_callback(self, tenant_id, status):
if status == 'violation':
self.pause_replay(tenant_id)
Operational Checklist for Successful Legacy-to-Cloud Migration with Event Backlog Recovery
- Assessment & Discovery:
- Inventory legacy event queue systems and backlog characteristics.
- Map tenant boundaries and identify critical workloads.
- Runbook Development:
- Draft replay procedures with target SLAs, rollback conditions, and handover points.
- Ensure clarity on distributed ownership roles and communication channels.
- Architecture Setup:
- Implement tenant-aware event bus with monitoring and replay orchestration layers.
- Integrate SLA monitoring dashboards with real-time backlog visibility.
- Testing & Validation:
- Run replay scenarios under controlled testing environments simulating backlog surges.
- Perform incident injection and recovery drills with team participation.
- Phased Rollout:
- Deploy migration in staged tenant batches, enforcing quality gates per stage.
- Monitor SLA adherence, adjusting replay rates and rollback procedures as needed.
- Post-Migration Review:
- Conduct retrospectives to analyze backlog recovery effectiveness and SLA impact.
- Refine runbooks, replay orchestration logic, and operational training based on findings.
Common Anti-Patterns and Pitfalls to Avoid
- Ignoring Tenant Isolation: Bulk replay without tenant segmentation leads to SLA violations and stakeholder dissatisfaction.
- Overlooking Distributed Runbook Synchronization: Disparate teams executing inconsistent recovery steps cause unpredictable outcomes and accountability gaps.
- Skipping Automation and Observability: Manual event replay and shallow monitoring increase incident response time and error rates.
- Rushing Rollout Stages: Accelerating migration without validated quality gates risks destabilizing production environments and customers' trust.
- Neglecting Backpressure Controls: Unbounded event replay floods processing pipelines, triggering cascading failures.
Conclusion: Enabling Predictable Multi-Tenant SaaS Migration in Fintech with Structured Event Backlog Recovery
Legacy-to-cloud migrations for fintech SaaS platforms represent a complex choreography of technical and operational challenges centered on event queue backlog management. By leveraging a staged rollout strategy, tenant-aware orchestration, and distributed yet standardized runbooks, organizations can elevate predictability in delivery commitments and operational resilience.
This approach directly improves lead qualification by providing transparent SLA guarantees and enables sales throughput uplift through minimized downtime and incident impact. Internal APIs for rollback control, continuous monitoring integration, and multi-layered test validation are necessary enablers of successful migration.
For teams pursuing a comprehensive modernization journey, exploring further architectural insights and practical tools is essential. Discover how our expert services can help implement robust migration programs to future-proof your fintech SaaS platform.
For deeper technical reference on migration workflows and orchestration models, please review our detailed case study on Legacy System Migration Blueprint and complement your knowledge with our blog article on Engineering Process Audit Initiatives: Microservices Consolidation. Additionally, insights on latency troubleshooting in complex automation pipelines are available in our Latency Troubleshooting and Optimization guide.
Implementation Example: Tenant-Specific Backlog Replay Steps
Implementing an effective tenant-specific backlog replay process requires a clearly defined sequence of operational steps tailored to individual tenant profiles and their unique SLAs. Below is an outline of a practical implementation checklist that can be embedded within the replay orchestration system:
- Step 1: Tenant Backlog Assessment
- Query tenant event queue depths and classify backlog severity: normal, warning, critical.
- Decide on replay necessity based on tenant SLA thresholds and business priority.
- Step 2: Pre-Replay Validation
- Verify resource availability in processing microservices to avoid overload.
- Check tenant data version compatibility and schema alignment.
- Step 3: Controlled Backlog Replay Execution
- Initiate replay batches respecting tenant-specific rate limits.
- Use quality gates to monitor data correctness and failure rates within each batch.
- Pause or scale down replay speed upon SLA violations or errors.
- Step 4: Post-Replay Verification and Audit
- Validate tenant data state consistency post-replay using hash checksums or reconciliation queries.
- Log replay metrics and anomalies for audit and continuous improvement.
- Notify distributed owners of replay success or required follow-up actions.
Checklist: Monitoring and Alerting Setup for Event Queue Backlog
Robust monitoring and alerting mechanisms are crucial to detect and mitigate event queue backlogs before SLA breaches occur. A practical checklist for configuring this includes:
- Metric Collection
- Event queue sizes per tenant, aggregated and granular.
- Event processing latencies and throughput rates.
- Error rates and retry counts during event processing.
- Threshold Definition
- Configure dynamic thresholds based on tenant SLA tiers.
- Implement multi-level alerts: warning, critical, action-required.
- Alerting Channels
- Integrate alerts into team communication platforms with role-based routing.
- Enable escalation policies escalating long-standing issues to senior operations.
- Dashboarding
- Develop tenant-segregated dashboards highlighting backlog trends and SLA compliance.
- Display replay orchestration status and ongoing recovery actions.
Anti-Pattern Spotlight: Ignoring Slow Consumer Patterns
One common pitfall during migration is neglecting to identify slow tenant consumers or processing bottlenecks that cause growing backlogs. Typical symptoms include persistent backlog growth despite replay efforts and frequent SLA alerts.
Steps to avoid this anti-pattern:
- Implement per-tenant consumer health checks to detect slowdowns.
- Analyze processing logs to identify bottleneck microservices.
- Throttle or queue inbound events dynamically based on consumer readiness.
- Coordinate with tenant teams for remediation or scaling plans.
Advanced Strategies: Automated Rollback and Reconciliation
To minimize risk during event backlog replay, consider implementing automated rollback and data reconciliation mechanisms as part of the resilience plan:
- Automated Rollback:
- Maintain versions or snapshots of tenant data states prior to replay.
- Incorporate logic in the orchestrator to revert tenant data upon failed replay or detected SLA violation.
- Integrate rollback triggers with alerting and incident response workflows.
- Data Reconciliation:
- Set up periodic audits comparing legacy and new system state to identify divergence.
- Use reconciliation results to fine-tune replay logic, filter duplicate events, and adjust event schema transformation rules.
- Enable automated anomaly detection to prevent silent data inconsistencies.
Key Performance Indicators (KPIs) for Migration Success Measurement
Tracking relevant KPIs during and after migration informs decision-making and continuous improvement:
- Backlog Recovery Time: Time taken to fully clear tenant-wise event backlog after triggering replay.
- SLA Adherence Rate: Percentage of tenants meeting defined processing latency and throughput SLAs during migration.
- Incident Frequency: Number of replay-related failures, rollbacks, or escalations per migration phase.
- Operational Automation Coverage: Share of replay orchestration and monitoring tasks automated versus manual interventions.
- Customer Impact Metrics: Measurable changes in tenant satisfaction scores or reported issues related to migration events.
Regular KPI reviews facilitate prioritization of remediation, runbook updates, and tooling investments aiming for continuous architectural and operational excellence.
Conclusion: Sustaining Operational Excellence Post-Migration
The migration strategy outlined should not only be seen as a finite project but as an evolving operational capability essential for sustaining a scalable, resilient multi-tenant SaaS platform. Ongoing investment in orchestration automation, distributed ownership enabling, and proactive SLA-driven backlog management will empower fintech SaaS providers to quickly adapt to changing workloads and evolving customer demands.
Additionally, embedding lessons learned from backlog recovery scenarios into development and release cycles ensures higher system quality and faster incident resolution, amplifying business value realized from cloud modernization.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.