Integrating machine learning (ML) into SaaS solutions elevates product value through automation, predictive analytics, and personalization. However, the addition of ML pipelines introduces complex latency, cost, and observability constraints that must align with enterprise Service-Level Agreements (SLAs). From an architecture standpoint, the key challenge lies in crafting a resilient, cost-effective cloud platform that supports dynamic routing and comprehensive entitlement governance without jeopardizing SLA commitments.
Lessons from multi-tenant SaaS deployments emphasize the necessity of moving beyond static routing towards policy-driven API gateways, critical for ML workloads that exhibit variable compute demand, intermittent data access requirements, and sensitive billing triggers.
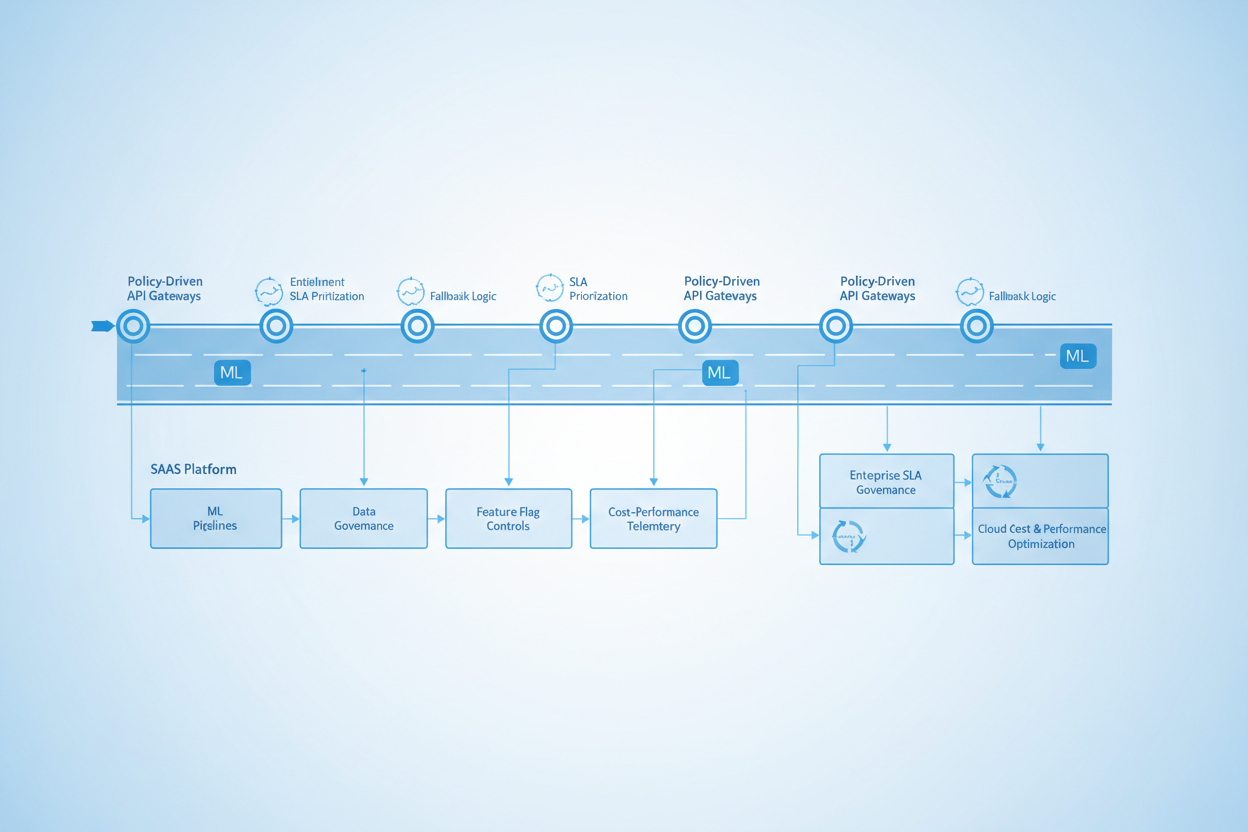
Key architectural components for ML-ready SaaS under SLA governance:
- Policy-Driven API Gateways: Implement routing policies that dynamically balance ML request prioritization, entitlement checks, and fallback scenarios to mitigate failure cascades.
- Cost-Performance Telemetry: Embed granular metrics collection correlating cloud spend and ML inference latency, feeding automated SLA alerting.
- Feature Flag and Rollout Controls: Enforce safe deployment through canary releases with rollback rehearsals, especially where ML model versions impact billing and SLA outcomes.
- Data Governance in ML Pipelines: Ensure data quality, lineage, and clipped quotas to prevent data spikes triggering unbounded dynamic scaling or overbilling.
These components demand tight integration with entitlement engines and billing reconciliation modules to avoid revenue leakage and SLA violations during ML feature rollouts.
Market Gap: Addressing the Lack of ML-Specific SLA Playbooks in SaaS Ecosystems
Despite increasing adoption of embedded ML, the SaaS market reveals a significant gap: enterprises struggle to reconcile ML-induced complexity with stable SLA governance and predictable cloud spend. Traditional API management and SaaS architectural patterns insufficiently address the coupling of ML model operational variability with billing edge-case stabilization.
Our analysis of real-world failure modes from production ML SaaS platforms uncovered common pitfalls:
- Uncontrolled ML traffic spikes causing entitlement breaches and unplanned cost overruns.
- Inadequately versioned API gateways leading to billing mismatches with ML feature toggles.
- Weak rollback rehearsals when deploying new ML models, resulting in latency SLA breaches.
- Insufficient routing policies that fail to degrade gracefully under ML microservice faults.
Consequently, enterprise customers face unpredictable billing combined with delayed feature delivery and customer dissatisfaction.
Closing this market gap requires an architecture blueprint embedding advanced API gateway policy engines, supporting ML workload awareness, and ensuring robust SLA observability integrated with cost governance.
Geo Differentiation: Designing ML-Ready SaaS for Regionally Diverse Cloud Costs and Performance Constraints
Cloud cost and latency profiles vary significantly across geographic regions, impacting the design decisions for ML-ready SaaS platforms targeting global enterprises. For example, deploying ML inference engines regionally can reduce latency but increase overall cloud service costs and data synchronization complexity.
Architectural trade-offs to consider include:
- Regional API Gateway Policies: Tailor routing rules per geography to direct ML requests to nearest model replicas or fallback pathways considering local SLA agreements.
- Cost-Aware Load Balancing: Employ hybrid policies that balance performance and cloud cost thresholds, dynamically throttling ML call volumes in cost-sensitive regions.
- SLA Tiering by Geography: Implement SLA governance layers that align service entitlements and monitoring granularity with regional compliance and performance mandates.
For regions with weaker rollback rehearsal histories, reinforce blue-green or canary strategies coupled with API gateway throttling to limit blast radius. These practices reduce escalation risks amidst ML model updates impacting billing or performance.
Pricing Impact: Measuring the Real Cost of ML-Driven Feature Delivery in SaaS Environments
Integrating ML features introduces volatility in cloud resource consumption that directly affects SaaS platform pricing strategies. Enterprise customers demand clear, stable pricing models reflecting actual ML workload use without surprise overcharge scenarios.
Key lessons include:
- Implement granular entitlement meters: Align ML inference usage and associated cloud costs with billing triggers defined in the API gateway policy engine.
- Establish cost-performance trade-off dashboards: Provide operational teams real-time visibility into ML workload cost-impact and latency SLA conformance versus budget.
- Use dynamic quota enforcement: Prevent runaway ML batch inference jobs or model training calls that spike costs through API gateway policy controls.
Without this visibility and control, the SaaS supplier risks either overcharging, damaging customer trust, or degrading profitability by absorbing cost overruns. Architecture must embed these controls tightly into the API gateway and cloud resource orchestration layers.
Adoption Plan: Safe Rollout of Policy-Driven API Gateway Routing for ML Workloads
Adopting a policy-driven API gateway suitable for ML workloads and enterprise SLA governance requires a methodical, phased plan focused on controlled risk and verification:
- Discovery and Baseline: Catalog current API gateway capabilities, ML workload patterns, cloud cost profiles, and SLA definitions.
- Policy Engine Prototype: Develop a dedicated ML-aware routing policy module that integrates entitlement checks, fallback routing, and throttling based on ML model status.
- Telemetry Integration: Instrument API gateway and ML microservices for end-to-end SLA and cloud expense telemetry with automated anomaly detection.
- Staged Deployments: Employ canary releases of the policy engine targeting less critical ML workflows with observability and rollback rehearsals.
- Feedback Loops: Use data-driven insights to refine policies, throttles, and quota limits before full-scale production rollout.
- Governance and Training: Align DevOps and Product teams on SLA governance practices, policy updates, and incident response playbooks.
Documenting rollout progress and failure modes is essential to improve future ML feature delivery speed while maintaining SLA compliance.
Checklist for rollout success:
- Defined SLAs and cost budgets per ML pipeline
- Integrated policy-driven routing and entitlement enforcement
- Automated rollback rehearsals with real data
- Incorporated telemetry and alerting for cost-SLA deviations
- Governance model supporting policy audits and updates
Roadmap: Technical Blueprint for ML-Ready SaaS Architecture Maturing to Enterprise SLA Governance
The roadmap unfolds across four phases, refining cloud cost and performance optimization driven by robust API gateway policies:
Phase 1: Foundation and Telemetry
- Implement detailed metrics collection for ML workload latency and cloud cost volumes.
- Establish a centralized SLA dashboard for early warning detection.
- Deploy API gateway instrumentation for traffic shaping and fallback routing prototypes.
Phase 2: Policy Engine and Entitlement Integration
- Develop policy-driven routing with ML entitlement gates.
- Introduce dynamic quota management tied to business billing events.
- Validate rollback processes in staging for ML model and routing policy updates.
Phase 3: Geo-Aware and Cost-Aware Enhancements
- Extend routing policies to support geo-distributed ML microservice deployment.
- Integrate cost-throttling capabilities aligned with region-specific SLA tiers.
- Refine SLA governance automation with incident prioritization including ML impact metrics.
Phase 4: Continuous Optimization and Automation
- Implement AI/ML-driven policy tuning for cloud cost and latency minimization.
- Formalize governance playbooks embedding lessons learned for new ML service onboarding.
- Align product roadmap with architecture to accelerate ML feature delivery safely and predictably.
Architects should continually revisit earlier phases to incrementally strengthen SLA resilience and control over ML-driven cloud expenditures.
Practical Implementation Details and Anti-Patterns
Implementing Policy-Driven API Gateway Routing for ML Traffic
A practical example includes:
def route_ml_request(request):
user_entitlements = fetch_entitlements(request.user_id)
model_version = extract_model_version(request)
if not user_entitlements.is_allowed('ml_feature'):
return reject_request('Unauthorized ML feature access')
if is_model_version_deprecated(model_version):
return route_to_fallback_service(request)
if exceeds_quota(request.user_id):
return throttle_request('Quota exceeded')
return forward_to_ml_inference(request, model_version)
This layered enforcement within the API gateway ensures only entitled, quota-compliant ML requests reach the inference service, reducing billing errors and latency impacts.
Anti-Patterns to Avoid
- Monolithic API gateway logic: Avoid embedding rigid routing logic without configurability, which hampers agility in ML model updates.
- No rollback rehearsals: Deploying ML routing policies or models without staged rollbacks increases likelihood of SLA breaches.
- Opaque billing pipelines: Lack of transparency in ML usage metering leads to frequent disputes and loss of trust.
- Ignoring geo cost variance: Uniform policy deployment across regions without cost-aware tuning inflates expenses uncontrollably.
Further Reading and Resources
- Performance Monitoring Dashboards for Multi-Tenant Systems: Learn about SLA observability for complex SaaS platforms.
- Governance-Centric Observability in SaaS Platforms: Dive deeper into governance models foundational for SLA governance.
- Partner API Onboarding with Quota Controls: Explore strict control practices applicable to ML feature entitlement enforcement.
To explore tailored ML-ready SaaS architecture strategies custom-fitted to your enterprise's SLA governance goals, visit our Services page. Our team specializes in architecting scalable, cost-effective SaaS platforms with embedded ML workloads, policy-driven API gateway routing, and comprehensive SLA governance frameworks.
Scaling ML-Ready SaaS with Predictive SLA Violation Mitigation
Beyond reactive monitoring, implementing predictive analytics to preempt SLA violations offers significant business value. This involves leveraging historical telemetry data and ML models embedded within the platform to forecast potential breaches in latency or cost thresholds before they occur.
- Data Collection: Continuously store granular logs of API gateway routing decisions, ML inference latencies, model utilization, and cloud resource consumption.
- Feature Engineering: Extract predictive features such as request volume patterns, model degradation signals, and quota exhaustion trajectories.
- ML Model Training: Develop supervised models identifying leading indicators of SLA violations, retrained periodically using production data.
- Integration with Policy Engine: Embed predictions as inputs to the policy engine, allowing temporary throttling or fallback routing to maintain SLA compliance.
Implementing this capability enables proactive operational responses, minimizing customer-impacting incidents and optimizing cloud spend. It also empowers cross-functional teams with early insights to adjust capacity or rollout schedules.
Implementing Incremental Feature Delivery Using Policy Flags
To accelerate ML feature deployment while managing risk, integrate feature flags controlled by API gateway policies. This approach allows selective exposure of new ML models or routing rules to defined customer segments or internal test groups.
- Flag Definition: Define feature flags corresponding to ML routes or model versions, stored in a centralized configuration service.
- API Gateway Evaluation: Extend the policy engine to check active flags per request scope, including user groups, geographic region, or subscription tiers.
- Gradual Rollout: Initially enable new features for small percentages of users or specific environments, monitoring impact with telemetry.
- Automated Rollback: Pair feature flags with automated rollback triggers on SLA deviation or cost spike detection.
This strategy reduces risk exposure, enabling rapid experimentation and validation of ML innovations aligned with SLA commitments and cost budgets.
Designing Multi-Tenant ML Workloads with SLA Isolation
For SaaS platforms serving diverse customers with distinct SLA profiles, isolating ML workloads per tenant is crucial to avoid cross-tenant SLA interference and unpredictable cost allocation.
- Namespace Separation: Architect ML microservices and model deployments to segregate tenant workloads logically via namespace or tenant ID routing.
- Quota Enforcement: Implement per-tenant quotas in API gateway policies controlling ML request rates, model invocations, and data volume processed.
- Cost Attribution: Integrate precise cost metering by tenant to enable transparent billing and SLA enforcement.
- SLA Profiles: Maintain tenant-specific SLA definitions in the policy engine, enabling differentiated routing and prioritization.
This ensures that high-priority or premium tenants receive guaranteed ML performance, while also preventing noisy neighbor effects that degrade overall platform reliability.
Automated Incident Response and SLA Recovery for ML Services
Incorporate automated incident detection and remediation workflows triggered by SLA deviations or policy enforcement events to reduce MTTR (mean time to recovery).
- Alerting Integration: Feed API gateway and ML service telemetry into centralized alerting systems configured with SLA thresholds and cost limits.
- Runbook Automation: Automate common remediation actions such as throttling adjustment, model rollback, or scaling ML inference clusters.
- Incident Playbooks: Define structured workflows for incident handlers that include triggering safe fallbacks or notifying impacted customers.
- Postmortem Analysis: Capture incident data to refine policies, update SLA definitions, and improve predictive models.
This operational discipline transforms SLA governance from a passive tracking exercise into a dynamic capability embedded within the ML-ready SaaS platform.
Checklist for Operational Readiness of ML-Ready SaaS Platforms
- Comprehensive SLA definitions including latency, throughput, availability, and cost thresholds for ML workloads.
- Robust API gateway policy engine with ML-aware entitlement, quota, and fallback routing capabilities.
- Real-time telemetry visibility for cloud cost, ML inference performance, and SLA adherence.
- Predictive analytics embedding SLA violation alerts into operational workflows.
- Controlled feature flag system enabling incremental ML feature rollout and safe rollback.
- Tenant isolated ML workload architecture supporting differentiated SLA profiles and cost attribution.
- Automated incident response playbooks reducing MTTR and customer impact.
- Governance framework ensuring regular policy audits, training, and cross-team alignment.
Summary
Designing and operating ML-ready SaaS platforms under strict enterprise SLA governance and cloud cost management requires a multi-dimensional approach. Embedding a policy-driven API gateway capable of fine-grained routing, entitlement enforcement, and dynamic quotas establishes a resilient foundation.
When combined with comprehensive telemetry, predictive SLA violation models, incremental delivery via feature flags, and tenant isolation, SaaS providers can confidently scale ML workloads without sacrificing performance or profitability.
Continuous automation of incident response and governance ensures alignment of technical architecture with evolving business priorities.
Following the checklist and roadmap phases outlined maximizes chances of successful adoption and long-term operational excellence in delivering ML-enhanced SaaS capabilities aligned with stringent SLAs and cost budgets.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.