Constructing a resilient full-stack architecture for AI knowledge assistant platforms entails balancing complex business goals such as billing stabilization and support consistency against the operational constraint of managing high-cardinality telemetry and noisy alerts. This review starts by framing the core architecture principles tailored to partner network automation and knowledge base governance for support teams.
Core Architecture Goals and Constraints
- Stabilize billing and entitlement edge cases: Address uncommon but business-critical scenarios in billing and partner entitlements that usually trigger operational noise and customer friction.
- Govern knowledge base for support consistency: Maintain a governed partner network knowledge ecosystem that minimizes discrepancies in support triage and empowers standardized resolutions at scale.
- Constraint - High-cardinality telemetry and noisy alerts: The telemetry design should avoid alert fatigue while safeguarding visibility into subtle failures and entitlement violations.
- Objective - Lower operational noise: Design for automated triage and clear escalation triggers to reduce manual effort and improve SLA compliance.
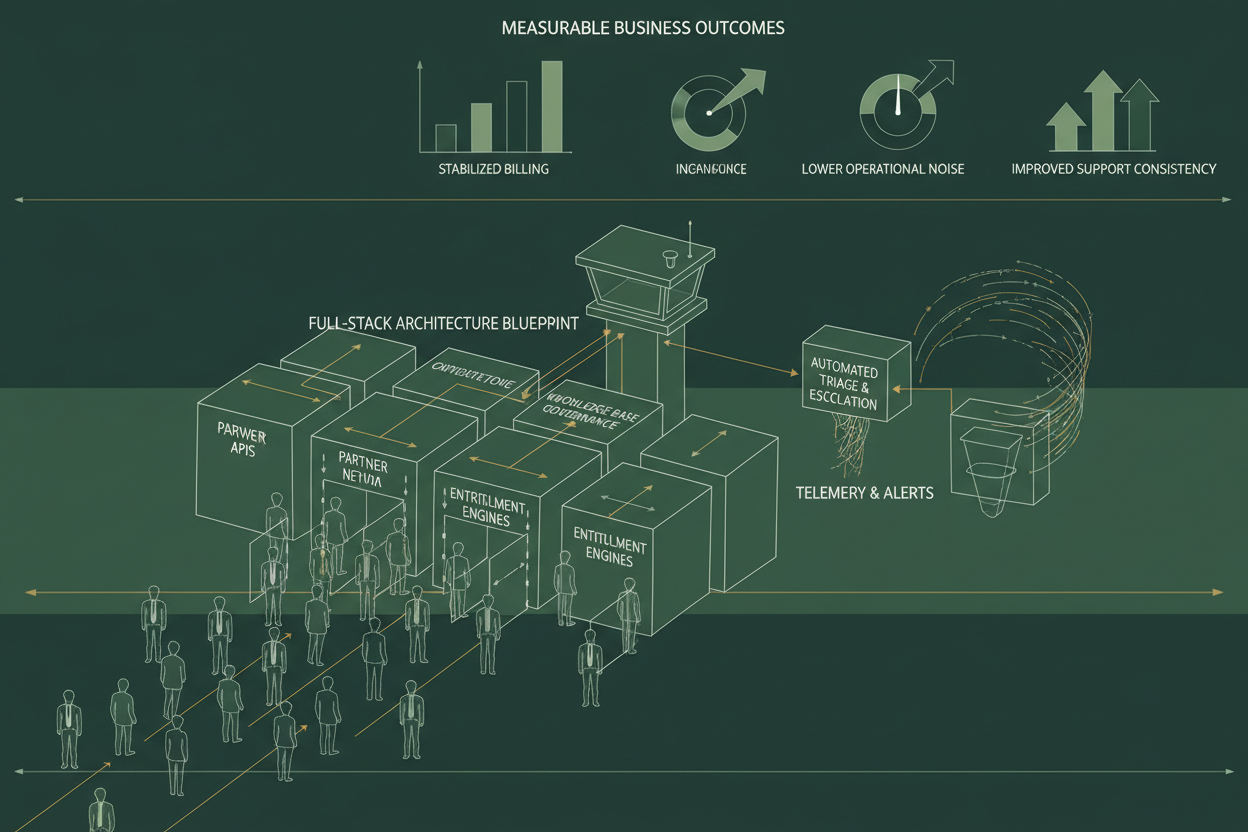
The architecture blueprint to achieve these objectives is cross-layered, spanning from backend services through data pipelines to user-facing knowledge bases and monitoring dashboards.
Components Breakout: From Partner Network API to Knowledge Base Governance
At the heart of the solution lies a multi-tier partner network automation stack. This includes partnership management APIs, entitlement rule engines, knowledge base authoring tools, and operational telemetry collectors.
Partner Network APIs and Entitlement Engines
The API layer must be designed with strict versioning and quota control to prevent partner onboarding inconsistencies that impact billing accuracy. The entitlement engine enforces dynamic, edge-case-aware rules with real-time validation and fallback mechanisms.
// Example snippet: Dynamic entitlement validation pseudo-code
function validateEntitlement(partnerId, entitlementRequest) {
const rules = fetchEntitlementRules(partnerId);
if (!rules) throw new Error('No rules found');
const isValid = rules.some(rule => rule.appliesTo(entitlementRequest));
return isValid;
}
Knowledge Base Governance Layer
Knowledge base consistency drives support efficiency. Implement governance through curated content lifecycle workflows, access controls, and partner collaboration portals. Enforce validation gates on knowledge articles before publication to reduce conflicting answers or outdated procedures.
Telemetry and Alerting Subsystems
Telemetry must capture detailed event metadata while aggressively filtering or aggregating non-actionable noise. Implement signal enrichment and alert suppression rules tailored to typical patterns of partner entitlement violations.
- High-cardinality key flattening
- Dynamic thresholding based on historical trends
- Contextual alert annotations aiding faster incident response
Data Pipelines: Managing Edge Cases and Telemetry Noise
Data pipelines act as the lifeblood for upstream and downstream components—feeding operational dashboards, automating incident responses, and orchestrating billing reconciliations.
Edge-Case Data Handling
Billing and entitlement anomalies often arise from edge-case transactions. Embed anomaly detection logic early in ingestion to flag peculiar patterns—such as rapid quota consumption or conflicting entitlement updates.
Data Normalization and Enrichment
Consolidate partner metadata and event streams into normalized schemas, enabling easier correlation across system boundaries. Enrich data with business context for improved root-cause analysis.
Pipeline Reliability and Idempotency
Incorporate checkpoints and idempotent processors to prevent duplicate billing triggers and inconsistent knowledge base updates, particularly in failure or retry scenarios.
Failure Modes Catalogue: Diagnosing Architecture Vulnerabilities
Identifying potential failure modes upfront is critical in a complex full-stack implementation where billing discrepancies or support inconsistencies can degrade trust.
Common Failure Modes
- False positive entitlement denials: Overzealous validation rules blocking legitimate partner requests.
- Knowledge base drift: Out-of-sync articles leading to inconsistent support decisions.
- Telemetry overload: Excessive alerts forcing operator fatigue and missed critical incidents.
- Data pipeline backpressure: Delays in anomaly detection and alert generation impacting SLA adherence.
Diagnosing Failures with Metrics and Logs
Design schemas for failure telemetry that embed correlation IDs spanning API requests through to billing outcomes and support tickets. Prioritize root-cause identification via event causality chains rather than symptom alerts alone.
Hardening Tactics: Implementation Quality for Stability and Scalability
Based on failure mode insights, apply hardened architecture patterns focusing on quality gates, automation, and continuous governance.
Governance and QA Checklists
- Entitlement rule auditing: Periodic reviews using test cases derived from historical billing edge cases.
- Knowledge base validation workflows: Enforced editorial reviews and automatic consistency checks before partner publication.
- Telemetry tuning: Quarterly recalibration of alert thresholds informed by alert volume and false positive rates metrics.
Automated Triage and Escalation
Implement automation to tag support tickets based on entitlement failure codes and telemetry signals. Integrate with escalation policies that factor in partner SLAs and priority levels.
Continuous Observability and Feedback Loops
Embed observability hooks into knowledge base usage analytics, partner API success rates, and billing reconciliation outcomes. Use these datasets to refine rules and thresholds in iterative governance cycles.
Outcome: Measurable Business Impact Through Architecture Excellence
Deploying this blueprint yields concrete operational benefits measurable in key performance indicators aligned with business goals.
- Reduced support noise: Lower volume of false alarms and quicker, consistent triage paths.
- Billing accuracy improvements: Fewer disputed charges thanks to stabilized edge-case handling.
- Partner satisfaction: Transparent knowledge base governance improves resolution confidence and onboarding experience.
- Operational resilience: Improved incident response times enabled through enriched telemetry and automated escalation.
This blueprint is not theoretical but shaped by real-world implementation scenarios. For instance, in a recent project, applying this architecture rigor around partner entitlement rules allowed the team to reduce billing exceptions by 28% within two quarters. Similarly, knowledge base governance cut average support call resolution times by 18%, directly feeding into improved SLA adherence.
To deepen your platform’s architectural maturity and operational excellence in partner network automation and AI knowledge assistant domains, explore our comprehensive services designed to tailor solutions to your unique business contexts.
For additional insights on integration frameworks simplifying complex SaaS architectures, see Integration Architecture for Multi-Tenant SaaS Admin Panels. To understand telemetry signal optimization techniques applicable here, review our Cloud Cost Optimization Action Plan. Lastly, explore practical partner API onboarding and quota control blueprints in Marketplace MVP Products for Services.
Best Practices for Implementing Partner Network Automation
Successful partner network automation in AI knowledge assistant platforms hinges on a systematic approach that balances agility with governance. Below are critical best practices to guide practical adoption and enhance architecture quality:
- Modular Service Design: Segment functionalities into clear, independently deployable services such as partner onboarding, entitlement management, and usage reporting. This improves scalability and fault isolation.
- Contract-Driven Development: Define explicit API contracts with detailed request/response schemas and versioning strategies. Use contract tests to validate integration points before deployment.
- Policy-as-Code: Embed business rules such as entitlement validation and quota enforcement directly into version-controlled policies that can be dynamically deployed with comprehensive audit trails.
- Idempotent Operations: Design APIs and data-processing steps to be idempotent, ensuring retries or duplicated messages do not lead to inconsistent billing or knowledge base states.
- Granular RBAC and Partner Segmentation: Implement access control tailored to partner roles and tiers, restricting sensitive data and governance actions appropriately.
- Incremental Rollouts and Canary Deployments: Mitigate risk by gradually releasing automation components to subsets of partners, enabling early detection of integration issues.
Concrete Steps for Onboarding Partner APIs with Quota Control
- Define Capabilities Matrix: Document partner-specific features, entitlement models, and expected usage patterns.
- Create API Version Roadmap: Plan API changes with backward compatibility windows and sunset policies communicated clearly to partners.
- Establish Quota Enforcement Thresholds: Set baseline, burst, and hard quota limits with automated alerts on threshold breaches.
- Implement Rate Limiting Middleware: Intercept partner requests using middleware that tracks usage and enforces quotas in real time.
- Develop Integration Test Suites: Simulate high-volume partner scenarios and edge cases to validate entitlement rules and quota rejection behavior.
- Monitor Telemetry and Feedback: Use real-time dashboards collecting quota usage, denial events, and API response performance to iteratively tune limits and policies.
Checklist for Knowledge Base Governance Hardening
- Content Ownership: Assign clear editorial responsibilities for each knowledge domain.
- Version Control: Utilize versioning and change tracking on all knowledge articles to enable rollback and audit.
- Validation Gates: Implement automated spellcheck, format compliance, and consistency rules as pre-publish steps.
- Review Cycles: Schedule periodic review sessions with SMEs and partner representatives.
- Collaboration Platform: Enable partner feedback and comment threads directly linked to articles for continuous improvement.
- Access Controls: Restrict article visibility and edits based on partner tier and operational role.
Advanced Telemetry Strategies for Reducing Noise and Improving Signal
Effective telemetry architecture transforms raw data into actionable intelligence while minimizing operator fatigue. Consider these implementation techniques:
Dynamic Alert Suppression Logic
- Temporal Correlation: Suppress alerts for transient spikes by grouping events occurring close in time before triggering notification.
- Context-Aware Filters: Use environment, partner, and service state context to avoid repeating alerts for known issues already under investigation.
- Severity Tiers: Assign alert severity based on impact and recurrence, enabling tiered response priorities.
Enrichment and Aggregation
- Event Flattening: Reduce high-cardinality fields by consolidating correlated parameters into concise composite keys.
- Correlation Identifiers: Propagate unique transaction IDs through API calls, billing events, and support tickets for unified tracing.
- Business Context Tagging: Attach metadata like partner SLA level, entitlement tier, and billing cycle to telemetry events for smart filtering.
Contextual Alert Annotation
- Root Cause Suggestions: Include links to related knowledge base articles and historical incident data in alert descriptions.
- Impact Scoring: Calculate and display estimated partner or revenue impact of an incident to aid prioritization.
- Suggested Escalation Paths: Present recommended operators and support tiers for escalation based on alert type.
Automating Incident Response and Billing Reconciliation
Automation accelerates resolution and reduces human error in complex operational workflows.
Incident Response Automation Steps
- Intake: Ingest telemetry signals and partner APIs failures automatically into incident-tracking systems.
- Classification: Use rule-based or ML classifiers to categorize incident severity and type.
- Ticket Routing: Automatically assign tickets based on partner SLAs and historical resolution teams.
- Remediation Scripts: Trigger automated corrective actions for common entitlement inconsistencies or knowledge base refreshes.
- Escalation: Implement timed escalation policies requiring manual review if auto-remediation fails.
- Feedback Loop: Capture resolution outcomes and feed into policy fine-tuning and knowledge updates.
Billing Reconciliation Automation Checklist
- Data Consistency Checks: Automated audits comparing entitlement logs against billing records.
- Discrepancy Reporting: Scheduled reconciliation reports highlighting variances for manual review.
- Rollback Procedures: Automated rollback or adjustment workflows triggered upon detected billing exceptions.
- Audit Trail Generation: Log all reconciliation steps with immutable IDs for compliance and dispute support.
- Regular Policy Review: Align reconciliation rules with evolving entitlement and partner agreements.
Scaling Architecture for Long-Term Maintainability
As partner networks grow in volume and complexity, architectural decisions must account for scalability without compromising governance.
Key Architecture Scaling Strategies
- Event-Driven Microservices: Employ event brokers to decouple services, allowing independent scaling of billing, entitlement, and knowledge base modules.
- Data Partitioning: Shard telemetry and billing data by partner or region to optimize query performance and reduce bottlenecks.
- Policy Distribution: Use centralized policy repositories with distributed caches close to enforcement points for low-latency validation.
- Automated Testing at Scale: Develop mass integration and chaos-testing scenarios simulating partner API behavior and data surges.
- Runbook Automation: Embed operational knowledge into hands-free recovery and incident diagnosis scripts to reduce manual overhead.
Anti-Patterns to Avoid in Partner Network Automation
- Monolithic Entitlement Engines: Large, tightly coupled codebases slow feature updates and increase risk from single points of failure.
- Static Quota Configuration: Rigid limits cause frequent false positives or negatives in partner usage validation.
- Unfiltered Telemetry Floods: Collecting all data without prioritization leads to alert fatigue and obscured critical signals.
- Manual Knowledge Base Updates: Lack of automation increases drift and inconsistent partner experience.
- Overreliance on One-Time Policies: Failure to continuously refine rules based on live feedback and analytics leads to stale governance.
Each of these pitfalls can erode operational stability and partner trust, underscoring the importance of the architecture-first governance model.
Summary and Next Steps
Building a resilient, governable partner network automation platform requires extending beyond technology into disciplined operational processes and continuous feedback loops. This article has provided practical implementation advice, concrete checklists, anti-pattern warnings, and architecture scaling guidance.
To further accelerate adoption and drive measurable business value, teams should consider formalizing:
- Cross-functional governance councils including product, engineering, support, and partner management.
- Automated metric and log dashboards reflecting both technical health and business KPIs.
- Regular policy retrospectives leveraging incident learnings and partner feedback.
- Incremental refactoring plans targeting known failure modes and bottlenecks.
Following this structured blueprint will stabilize billing accuracy, streamline support consistency, and enhance partner satisfaction—all key outcomes for AI knowledge assistant platforms operating in dynamic enterprise environments.
Explore our services to tailor this blueprint into actionable roadmaps and implementation engagements aligned with your platform’s unique maturity and partner ecosystem.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.