Checkout processes, especially in high-volume B2B SaaS environments, are prime candidates for continuous experimentation and optimization. Webhook-driven architectures offer substantial advantages in decoupling services and enabling real-time event propagation. However, they also introduce complexity and potential for integration brittleness. A well-defined experiment map is crucial for navigating these complexities while adhering to strict SLA penalties and uptime commitments.

The Customer Journey View: Identifying Optimization Opportunities
A detailed understanding of the customer journey during checkout forms the bedrock of any successful optimization strategy. Instead of viewing checkout as a monolithic block, dissect it into individual stages:
- Product Selection & Cart Initialization: How quickly can users find, evaluate, and add products to their cart?
- Address & Payment Information: Are forms optimized for various device types? Are address validation services integrated correctly to reduce errors?
- Order Confirmation & Fulfillment Initiation: Is the order summary clear and concise? Are users immediately informed about the next steps in the fulfillment process?
- Post-Purchase Notifications: How effectively are users kept informed about order status, shipping updates, and potential delays?
Each stage presents opportunities for improvement. Example: Reducing cart abandonment by streamlining the process of applying discount codes or offering tiered shipping options upfront.
Establishing Trust Signals: Mitigating Perceived Risk
Checkout processes demand user trust. Perceived risk can significantly increase abandonment rates. Building trust hinges on:
- Transparent Security: Clearly communicate data security measures, such as encryption and PCI compliance.
- Reliable Performance: Guarantee fast loading times and minimal downtime. Use a CDN and optimized database queries.
- Clear Return/Refund Policies: Make it easy for users to understand their rights and options.
- Social Proof: Display customer testimonials, reviews, and trust badges (e.g., verified business seals).
Employ techniques like A/B testing alternative trust messages based on visitor landing pages.
Risk Gates: Implementing Cancellation and Retry Strategies
In a webhook-driven architecture, asynchronous events like payment confirmations introduce asynchronous risk. Implementing robust risk gates is paramount. The following strategies are essential:
- Idempotency: Design webhook handlers to be idempotent, meaning they can safely process the same event multiple times without unintended consequences. Use unique transaction IDs to prevent duplicate order creation.
- Retry Policies: Implement exponential backoff retry policies with jitter to handle transient errors in external services or network connectivity hiccups.
- Dead-Letter Queues (DLQs): Route failed webhook events to a DLQ for manual inspection and resolution.
- Circuit Breakers: Protect your system from cascading failures by implementing circuit breakers that prevent further requests to failing services.
Here's a simplified example of a retry policy using a cloud message queue concept:
function processWebhookEvent(event) {
try {
// Attempt to process the event
success = doSomething(event);
if (!success) {
throw new Error("Processing failed");
}
} catch (error) {
// Increment retry count
event.retryCount = (event.retryCount || 0) + 1;
// Check if retry limit is reached
if (event.retryCount > MAX_RETRIES) {
// Send to DLQ
sendToDLQ(event, error);
return;
}
// Calculate backoff time (exponential with jitter)
let backoff = Math.pow(2, event.retryCount) * BASE_DELAY;
backoff += Math.random() * JITTER;
// Reschedule the event with a delay
scheduleEvent(event, backoff);
}
}
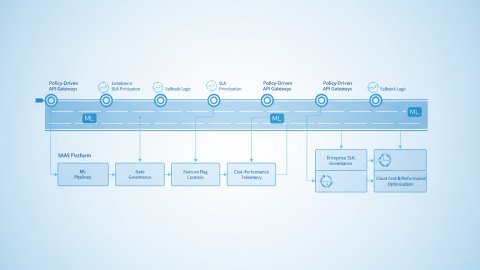
Backend Logic Shift: Policy-Driven API Gateway Migration
Conventional API gateways often rely on static routing rules. A policy-driven approach offers dynamic control over request routing and transformation based on runtime conditions and context. The migration to such an API gateway involves these key steps:
- Define policies: Express routing, rate limiting, authentication, and authorization rules as declarative policies. Use a domain-specific language (DSL) or configuration management system for policy definition.
- Policy engine: Integrate a policy engine into the API gateway to enforce policies dynamically. This engine evaluates policies against each incoming request and applies the appropriate actions.
- Context Enrichment: Enrich requests with context information (e.g., user roles, device type, geographic location) that can be used for policy decisions.
- Progressive Migration: Migrate incrementally, starting with less critical endpoints and gradually expanding coverage.
This is critical for improving platform audit readiness; policy enforcement provides a central location for compliance validation.
Orchestration Visibility: Service-Level Dashboarding and Alerting
Comprehensive service-level dashboards are indispensable for monitoring the health and performance of the checkout process and identifying potential bottlenecks. Key metrics to track include:
- Checkout Completion Rate: Percentage of users who successfully complete the checkout process.
- Abandonment Rate: Percentage of users who abandon the checkout process before completion.
- Error Rate: Frequency of errors encountered during checkout (e.g., payment failures, address validation errors).
- Latency: Time taken for each stage of the checkout process to complete.
- Webhook Delivery Success Rate. Ensure webhooks are being delivered reliably.
Configure alerts to trigger when key metrics deviate from established baselines. Integrate with incident management systems for rapid response to critical issues. Consider the insights discussed in Zero-Downtime SaaS Refactoring: Observability Coverage Matrix for Incident Response & SLA Governance for building a resilient alerting strategy.
Checklist: API Gateway Rollout and Audit Plan
- Define policy evaluation and enforcement points within the API gateway.
- Implement comprehensive logging and auditing of policy decisions.
- Design automated tests to validate policy correctness and performance.
- Establish clear ownership and responsibilities for policy management.
- Define a rollback plan in case of policy errors or unexpected behavior.
- Secure Security and Compliance Automation: Zero-Trust Operations Dashboard for Multi-System ROMI Reporting patterns.
- Integrate audit logging with existing SIEM solutions for centralized monitoring.
Recommendations: Optimization and Next Steps
Checkout optimization is an iterative process. Continuously monitor key metrics, analyze user behavior, and experiment with different optimization techniques. Regular A/B testing, combined with a policy-driven API gateway and robust risk mitigation strategies, is crucial for achieving and maintaining optimal checkout performance and reliability. This approach, centered around webhook reliability, addresses the intent to lower operational noise in support and triage functions, reducing the time spent chasing down issues arising from unreliable webhook integrations. For further enhancement in high-load scenarios, review High-Load campaign runbook: consolidating telegram support bot microservices for SLA transparency. Get in touch with our architecture team to optimize your services: Explore Services.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.
Support-to-sales handoff workflow
I configure the support-to-sales handoff so valuable requests do not get lost between systems and teams.
AI knowledge assistant
I connect an AI assistant to the team knowledge base so staff can find precise answers and procedures faster.