In Telegram partner network automation stacks, successful integration with third-party services underpins system resilience and operational efficiency. Post high-risk releases, stabilization is often undermined by brittle interfaces, opaque failure modes, and insufficient observability—leading to inconsistent support quality and unclear incident ownership.
This hardening guide prioritizes architecture-driven decisions with a focus on critical service surfaces. It accounts for constraints such as content operations running without unified quality gates and business goals aiming for measurable improvements in support first-response using AI assistance. Maintaining vendor-neutrality, this document refrains from prescribing specific technologies, instead drilling into architectural patterns, integration checkpoints, and operational tactics.
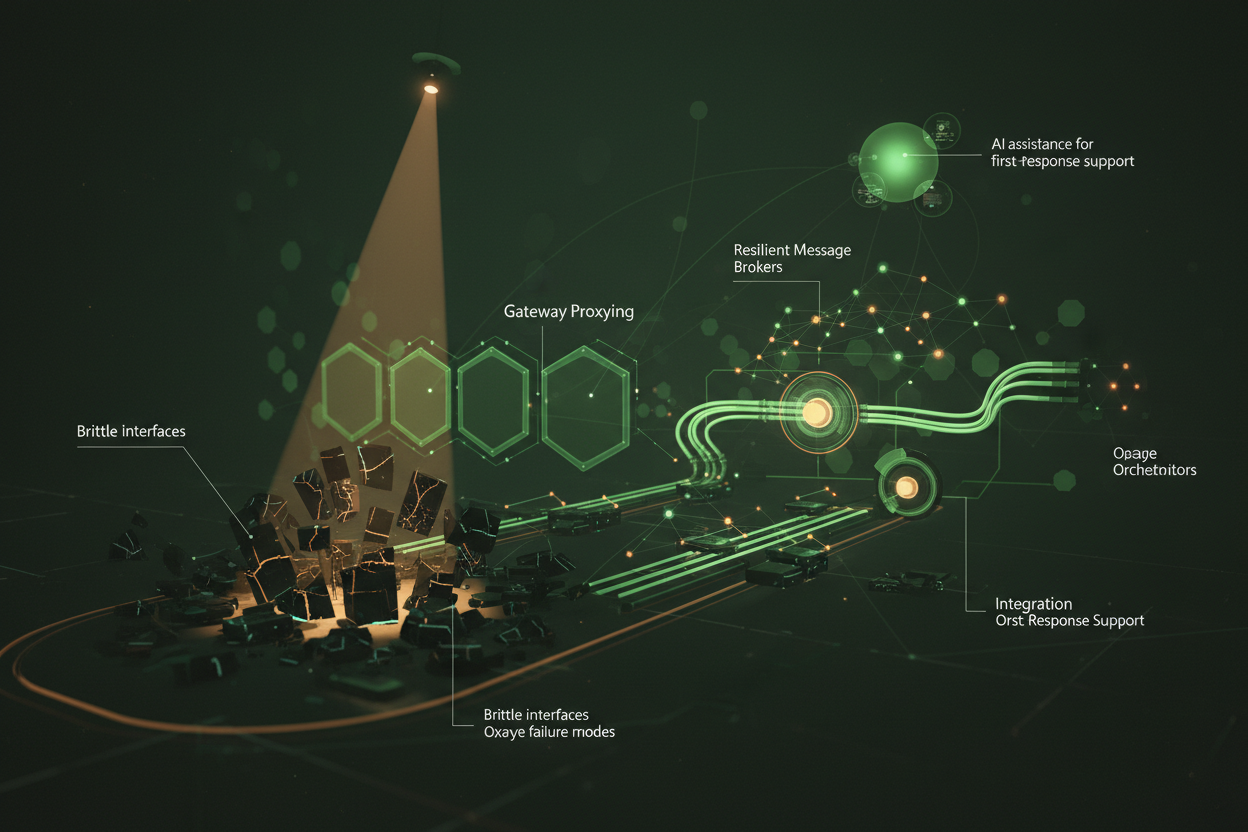
Core Architectural Components for Stable Integration
- Service Boundary Definition: Clearly demarcate where third-party systems interface, isolating integration points with well-defined API contracts and version control.
- Gateway Proxying: Employ an API gateway layer to centralize authentication, rate limiting, logging, and routing—enabling policy enforcement prior to service invocation.
- Resilient Message Brokers: Use durable and asynchronous event queues to decouple partners from direct synchronous dependencies, smoothing intermittent latency or outages.
- Integration Orchestrators: Deploy microservice layers or workflow engines to manage complex partner interactions, retries, and circuit breaker states.
- Observability Agents: Instrument telemetry for real-time performance, SLA tracking, and anomaly detection spanning integrated partners.
Focusing on these components sets a solid foundation to embed hardening tactics systematically.
Data Pipelines and Integration Surface Design
Third-party integrations are often data pipelines transforming, routing, and enriching partner-sourced events. Post-launch incidents frequently trace back to unhandled edge cases and data inconsistencies at these surfaces.
Checklist for Robust Data Pipeline Engineering
- Schema Validation: Implement strict input and output data validation aligned with shared API contracts; reject or quarantine malformed messages.
- Semantic Versioning and Compatibility: Use version-aware decoding to gracefully manage backward-incompatible changes without cascade failures.
- Idempotency Handling: Design APIs and consumers to be idempotent, preventing duplication or data corruption during retries.
- Error Channeling: Separate error streams for downstream reconciliation processes rather than dead-letter queues prone to silent data loss.
- Message Enrichment and Tagging: Add metadata tags for provenance, retry count, and anomaly flags to facilitate tracing and analytics.
For example, in Telegram partner stacks automating support bot workflows, such pipelines must feed AI-based response systems with timely, validated data ensuring clear contextual cues to improve first-response accuracy.
Typical Failure Modes and Anti-Patterns in Post-Release Automation Stacks
Identifying common failure modes accelerates early incident triage and informs preventive engineering controls. The following patterns emerged in field observations:
Frequent Failure Modes
- Protocol Drift: Silent API contract shifts by partners lead to unhandled edge cases, message rejection, or misrouting.
- Event Storms: Uncontrolled event bursts ignite cascading failures or resource exhaustion without backpressure mechanisms.
- Opaque Error Propagation: Surface errors conceal true root causes due to deep nested async callbacks without correlation IDs.
- Retry Storms: Naive retry policies trigger exponential load amplifications, compounding instability.
- Ownership Ambiguity: Lack of clear incident ownership delays response and recovery.
Anti-Patterns to Avoid
- Monolithic integration code mixing business logic and partner communication layers.
- Direct synchronous calls to third-party APIs without fallback strategies.
- Absence of idempotency or transactional semantics on critical data operations.
- Logging-only observability without actionable SLA metrics or incident playbooks.
- Lack of pre-release integration smoke tests aligned with live traffic patterns.
Addressing these early is crucial in Telegram stacks, especially post high-risk launches involving complex partner workflows.
Hardening Tactics: Concrete Steps for Stabilization and Incident Accountability
Following architectural baselines and failure analyses, the roadmap to hardening integrates both engineering improvements and operational governance enhancements:
1. Enforce Integration Quality Gates
- Define mandatory pre-release test suites simulating partner API changes and edge case data.
- Introduce contract-first API design with automated validation against partner schema registries.
- Implement staged rollout pipelines to surface integration issues with canary and shadow traffic replication.
2. Enhance Observability and Incident Triage
- Deploy SLA-aligned dashboards monitoring partner API latency, error rates, and volume anomalies.
- Instrument distributed tracing with unique correlation IDs spanning partner integration boundaries.
- Integrate AI-powered triage assistants trained on historical incidents for alert prioritization and first-response diagnosis.
3. Implement Clear Ownership and Accountability Models
- Assign dedicated integration owners responsible for partner liaison and issue resolution.
- Establish incident response playbooks with defined escalation paths and communication protocols.
- Use postmortem reporting templates aligned with root cause analysis and service improvements.
4. Apply Robust Failure Handling and Recovery Patterns
- Design circuit breakers and bulkheads isolating partner failures from core automation workflows.
- Implement exponential backoff with jitter in retry mechanisms to mitigate retry storms.
- Leverage message dead-letter queues with alerting and automated reconciliation triggers.
5. Continuous Improvement via Feedback Loops
- Schedule periodic architecture and process audits focusing on integration health metrics.
- Incorporate partner feedback sessions to align SLAs and interface expectations.
- Track long-term trends in support case volumes correlated to integration versions and deployment phases.
These tactics form the spine of stabilization efforts yielding sustained improvements in support quality and incident resolution cadence.
Outcome and Measurable Business Impact
Hardening critical third-party integration surfaces within Telegram partner network automation stacks delivers concrete operational benefits aligned with business intent:
- Improved First-Response SLA: AI-assisted support workflows reduce average response time by providing validated data context and automating triage.
- Reduced Incident Resolution Time: Clear ownership and enhanced observability enables faster root cause isolation and recovery action.
- Lower Failure Rates and Service Degradation: Architectural resilience minimizes downtime and impact on downstream AI and user-facing services.
- Greater Operational Predictability: Quality gates and continuous audits enable consistent integration performance under evolving partner conditions.
- Clearer Accountability Model: Incident ownership and root cause transparency strengthen cross-team collaboration and decision making.
Organizations advancing through this hardening playbook realize stabilized post-release environments that support growth, innovation, and higher customer satisfaction.
Next Steps: Implementing Best Practices and Supportive Services
Applying this guide into real-world Telegram partner network automation scenarios requires a tailored implementation path. Consider engaging specialized architecture services that provide:
- Integration architecture assessments and remediations tailored to your partner stack complexity.
- Custom observability blueprinting focused on your critical service surfaces and AI-enhanced monitoring.
- Incident response process designs including AI triage assistant integration.
- Stakeholder training on ownership models and escalation workflows aligned with business outcomes.
Explore how our professional services can accelerate your post-release stabilization journey with proven expertise and hands-on architectural leadership.
For a deeper dive on related architectural patterns and migration blueprints, visit these reference articles from our knowledge base:
- Microservice Orchestration with SLA: Migration Blueprint for Observability and Alerting in E-Commerce Warehouse Status Sync
- Security Control Uplift in Cloud-Native Telegram Partner Network Automation Stacks: A Knowledge Base Governance Framework Before Enterprise Onboarding
- Latency Troubleshooting and Optimization in Event-Driven Automation Pipelines for CRM and ERP Integration Estates
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.


