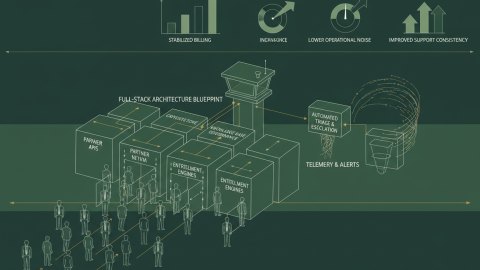
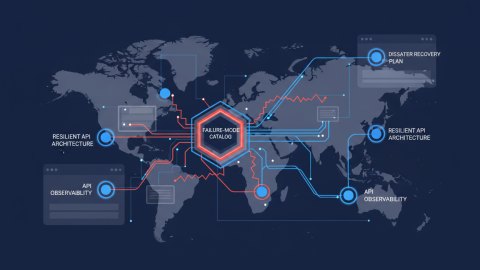
Before diving into implementation, ensure your team can answer these questions. This checklist ensures you're addressing observability with a business-first mindset.
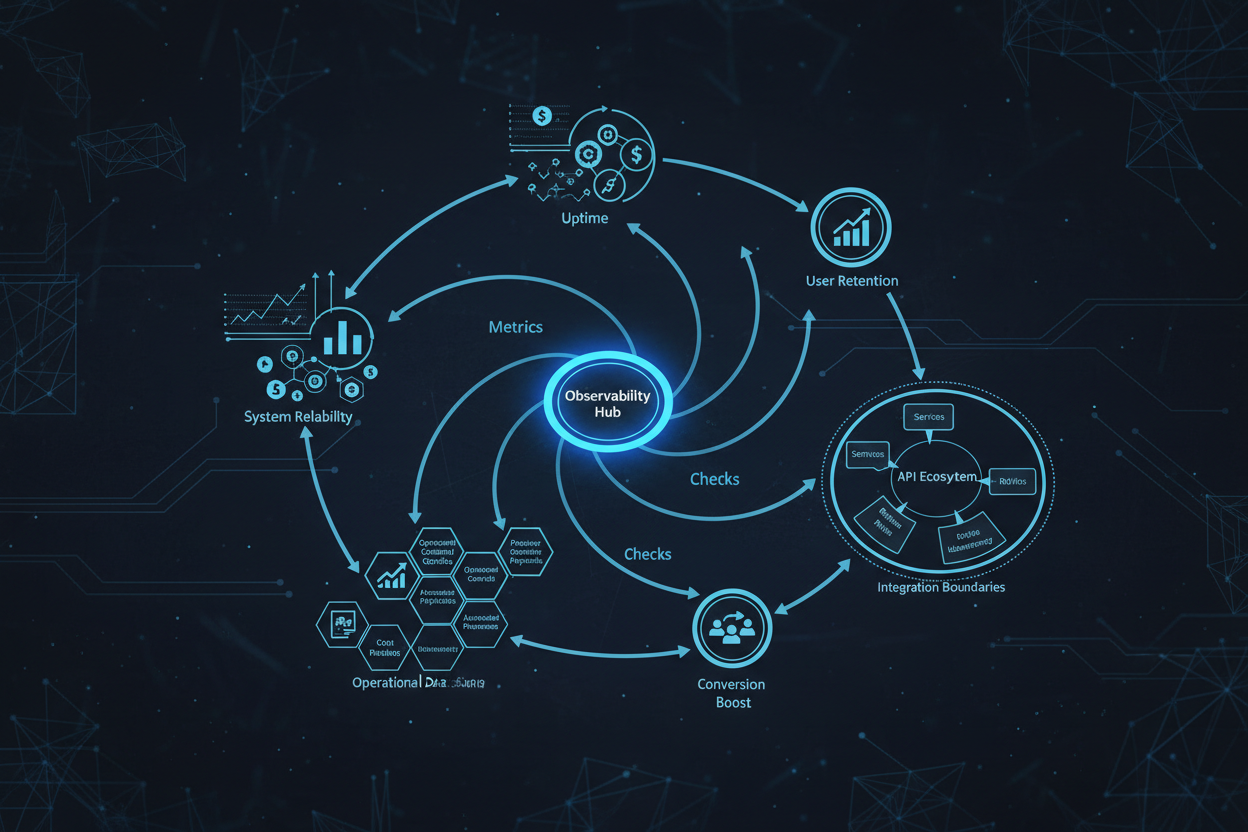
- Business Impact: Can you directly correlate specific metrics with key business KPIs (e.g., revenue, customer retention)?
- Automation Readiness: Are your alert thresholds and remediation scripts automated to minimize human intervention?
- Team Alignment: Is there a shared understanding across development, operations, and security teams of what constitutes a healthy system state?
- Data Sufficiency: Do you have enough historical data to establish baselines and detect anomalies accurately?
- Feedback Loops: How do you incorporate learnings from incidents into future system design and monitoring strategies?
Environment Checks: Laying the Groundwork
Before implementing any observability solution, I focus on these environmental aspects:
- Resource Allocation: Verify adequate CPU, memory, and storage are allocated to monitoring systems. Under-resourced observability tools provide inaccurate data, defeating the purpose.
- Network Configuration: Ensure proper network connectivity and bandwidth for metric transmission. Latency in metric delivery leads to delayed alerts and missed issues.
- Security Posture: Validate that monitoring tools adhere to security best practices, including encryption, access control, and regular vulnerability scanning. Observability mustn't become a security vulnerability itself, see Security-By-Design.
- Time Synchronization: Confirm all systems are synchronized to a common time source (e.g., NTP). Accurate timestamps are crucial for correlating events across different components.
- Configuration Management: Implement a system for managing and versioning monitoring configurations. This allows for consistent deployments and easy rollbacks.
Risk Rule Setup: Proactive Anomaly Detection
Defining targeted risk rules turns raw metrics into actionable insights. Consider this example scenario. An e-commerce platform experiences a 10% drop in conversion rate during peak hours for two consecutive days.
A basic alert would trigger, but a risk rule setup should proactively analyze:
- Is the issue isolated to a specific product category or user segment?
- Are there corresponding spikes in error rates or latency?
- Did a recent code deployment coincide with the conversion drop?
Translating this to a risk rule involves defining metrics like conversion rate, error rate, and latency, setting dynamic thresholds based on historical data, and correlating these metrics to proactively identify potential causes and prioritize investigation efforts, as described in Metrics-Driven Observability.
Anti-Pattern: Alert Fatigue
Avoid overwhelming teams with excessive alerts. Alert fatigue leads to ignored notifications and missed critical issues. Focus on high-signal alerts that directly impact business operations.
Integration Steps: Injecting Observability into the Workflow
Integrating observability involves several steps:
- Instrumentation: Instrument code to emit relevant metrics, logs, and traces. Use libraries and frameworks to simplify this process.
- Aggregation: Aggregate data from various sources into a centralized monitoring system. Choose a solution that scales to handle your data volume.
- Visualization: Create dashboards and visualizations to present data in an easily understandable format. This aids in identifying trends and anomalies.
- Alerting: Configure alerts to notify teams when critical thresholds are breached. Ensure alerts are actionable and provide sufficient context.
- Automation: Automate responses to common issues. This reduces manual intervention and improves system resilience, aligning with DevOps CI/CD for Peak Loads.
Monitoring Controls: Continuous Improvement
Observability isn't a one-time setup. Continuous monitoring and refinement are essential. Regularly review dashboards, alerts, and automation scripts. Adapt monitoring strategies as your system evolves.
- Performance Testing: Conduct regular performance tests to identify bottlenecks and optimize system performance.
- Load Testing: Simulate peak load conditions to ensure the system can handle increased traffic.
- Security Audits: Perform regular security audits to identify vulnerabilities and ensure compliance.
Conclusion
Building observable systems requires a holistic approach. It's not just about collecting metrics; it's about turning those metrics into actionable insights and automated responses. By focusing on business impact, automating remediation, and fostering team alignment, you can achieve operational excellence and drive better business outcomes. If you would like assistance in architecting your solutions, please review our services.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.