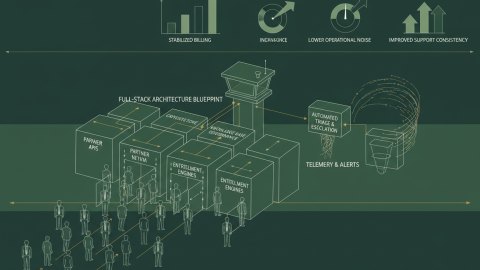
Observability. It's the buzzword that promises insight into your systems like never before. But the truth is, simply collecting *more* data doesn't guarantee operational excellence. What often happens is you drown in metrics, alerts become noise, and your team is still struggling to resolve issues efficiently. The core challenge becomes defining *what* to observe and *how* to translate that observation into actionable improvements.

Step-by-Step Lab: Building a Minimal Viable Observability Pipeline
I'll outline a lab-based approach to help you implement a basic observability pipeline. The aim is to measure its effectiveness as you scale.
Environment Setup: Containerized Microservices
For this example, consider a small cluster of containerized microservices. I recommend using Docker Compose to simulate a more extensive environment easily. You'll need:
- Three to five microservices (e.g., a user service, a product service, an order service)
- A message queue (e.g., RabbitMQ or Kafka for asynchronous communication)
- A database (e.g., PostgreSQL)
Sample Payloads: Generating Realistic Traffic
Creating realistic traffic patterns is critical for evaluating your observability setup. This could involve simulating user requests, background jobs, and database queries. Use tools like `locust` or `k6` to generate load based on defined scenarios. Ensure your sample payloads include a mix of successful and failing requests to realistically test your monitoring.
Risk Evaluation: Identifying Critical Failure Points
The central debate: where do you focus your observability efforts? Not every component is equally critical. Start with a risk assessment. Where are the most likely points of failure? What components have the biggest impact on user experience and revenue? Here's a checklist:
- **Identify Critical Components:** List the services vital for core business functions.
- **Assess Failure Impact:** Determine the consequences of each component's failure (e.g., revenue loss, user churn, data corruption).
- **Prioritize Monitoring:** Focus on the components with the highest impact and probability of failure.
For example, if your ordering service goes down, it directly impacts revenue. Therefore, it requires more detailed monitoring than, say, a less critical background process.
Logging Strategy: Structured Logging for Actionable Insights
Logs are a fundamental data source for observability. The key is structured logging. Instead of free-form text, use a format like JSON that enables easier parsing and querying. Consider these principles:
- **Consistency:** Use a consistent logging format across all services.
- **Context:** Include relevant context in each log entry (e.g., request ID, user ID, trace ID).
- **Levels:** Use appropriate log levels (e.g., DEBUG, INFO, WARN, ERROR) to filter efficiently.
Anti-pattern: Sticking to basic print statements without structured data. This makes analysis incredibly difficult and time-consuming.
Metrics: Choosing Meaningful Signals
Metrics provide aggregated views of system behavior. However, not all metrics are created equal. Focus on those that directly correlate with business outcomes. For example:
- **Latency:** Request processing time (e.g., p95 latency for API endpoints).
- **Error Rate:** Percentage of failed requests.
- **Resource Utilization:** CPU, memory, and disk usage.
- **Queue Length:** Number of messages waiting in the queue (for asynchronous systems).
A/B test different metrics. Track query/lookup performance. Does adding an index improve speed? Can you drop less used metrics that cost money to collect while adding no real value?
Practical Example: Slow Order Processing
Let's say your order processing latency spikes. Your metrics alert you to high latency in the `order` service. Using tracing, you can see that a specific database query is the bottleneck. Digging into the logs, you find that this query is frequently timing out due to high database load. You can then implement caching or optimize the query itself to resolve the issue.
Final Notes: Iterative Improvement and Team Alignment
Observability is not a one-time setup; it’s an ongoing process. Regularly review your metrics, alerts, and logging strategy. Is your team effectively using the observability data to resolve issues? Are you still getting valuable insights, or have you become overloaded with data?
The final question: Who owns observability? Successful observability requires collaboration between development, operations, and security teams. Define clear ownership and responsibilities to avoid knowledge silos.
Think of your observability efforts as an investment. Start small, focus on high-impact areas, and iterate based on real-world results. This will help you avoid the common pitfalls and achieve genuine operational excellence. Want to leverage some hands-on expertise? Explore our services to see how I can help your organization build a more resilient and observable system.
Consider these related topics: Navigating enterprise integration: playbooks for optimized operations and B2B SaaS Scalability: Architectural Trade-offs. For related concerns, read more on Product architecture for sustainable growth: Performance-Centric strategies.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.
Bitrix or website integration with marketplace API
I integrate marketplace APIs with your website or Bitrix so synchronization stops relying on manual workarounds.
Landing page redesign for conversion
I redesign key landing pages around decision logic so traffic does not stall in passive reading.