In today's competitive e-commerce landscape, real-time Return on Marketing Investment (ROMI) analytics is critical for optimizing checkout and conversion platforms. However, integrating these analytics into a high-availability microservices architecture poses significant challenges, especially when dealing with event queue backlogs and stringent data privacy requirements. This article provides a data-backed blueprint for building resilient and reliable ROMI analytics integration, focusing on practical implementation details and measurable outcomes.

Decision Framework: Balancing ROMI with Data Privacy
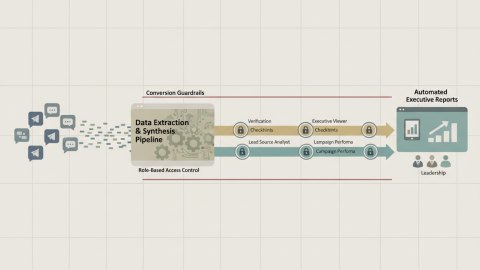
The first step is establishing a clear decision framework that balances the need for accurate ROMI data with the ethical and legal requirements of data privacy. This framework should define acceptable data collection practices, anonymization techniques, and data retention policies. A core principle should be minimizing the personally identifiable information (PII) collected while maximizing the value of the resulting analytics. For example, instead of tracking specific user IDs, aggregate data across user segments based on purchase history and demographics can be used. Statistically, this approach allows for robust trend analysis while significantly reducing privacy risks.
Implement data masking techniques at the API level to prevent sensitive data from reaching the analytics pipeline in the first place. Consider differential privacy techniques to add noise to the data, ensuring aggregated outputs do reveal the statistics without disclosing individual records.
- Checklist:
- Define clear data privacy policies aligned with legal requirements (e.g., GDPR, CCPA).
- Implement data anonymization and aggregation techniques to protect user privacy.
- Establish a process for data subject access requests (DSARs).
- Regularly audit data collection and processing practices to ensure compliance.
Risk Appetite: Defining Acceptable Downtime
A crucial aspect of designing high-availability systems is defining your organization's risk appetite regarding service downtime. For mission-critical e-commerce checkout flows, even brief interruptions can translate into significant revenue loss and customer dissatisfaction. Data shows that every second of delay in page load time can decrease conversion rates by as much as 7%. Therefore, a highly conservative risk appetite is generally warranted, aiming for near-zero downtime.
To quantify your risk appetite, consider the following factors:
- Estimated revenue loss per minute of downtime.
- Impact on customer satisfaction and brand reputation.
- Cost of implementing and maintaining high-availability solutions.
Based on these factors, define specific Service Level Objectives (SLOs) for your ROMI analytics integration. For example:
- Availability: 99.99% (less than 5 minutes of downtime per year).
- Latency: <200ms for data ingestion and processing.
- Data Accuracy: >99.9% (ensuring data integrity and consistency).
Geo Thresholds: Multi-Region Deployment Strategies
For e-commerce platforms serving a global customer base, geographical distribution of microservices is essential for minimizing latency and ensuring resilience against regional outages. Implementing a multi-region deployment strategy involves replicating your ROMI analytics microservices across multiple geographic regions. This approach ensures that if one region experiences an outage, traffic can be seamlessly routed to another region, maintaining service availability.
When designing your multi-region deployment, consider the following factors:
- Proximity to users: Choose regions that are geographically close to your primary customer base to minimize latency.
- Regulatory compliance: Select regions that comply with relevant data privacy regulations (e.g., EU, US).
- Infrastructure costs: Balance performance and compliance requirements with the cost of deploying and managing infrastructure in different regions.
Implement load balancing and traffic management techniques to automatically route traffic to the healthiest and closest region. For example, using DNS-based load balancing or a global load balancer (GSLB) can ensure that traffic is distributed efficiently across regions.
To ensure data consistency across regions, use a distributed database or data replication strategy. Data shows eventual consistency models are acceptable for ROMI analytics provided compensation mechanisms exist. Analyze specific workloads like batch update times.
Escalation Logic: Automated Incident Response
Even with robust high-availability measures in place, incidents can still occur. Effective incident management relies on well-defined escalation logic and automated response mechanisms. Implement a comprehensive monitoring and alerting system that proactively detects and alerts engineers to potential issues.
Your escalation logic should define clear roles and responsibilities for incident response, including:
- On-call engineers: Responsible for triaging and resolving incidents.
- Incident commander: Coordinates incident response efforts and ensures effective communication.
- Subject matter experts: Provide specialized knowledge and support.
Automate incident response tasks as much as possible, such as:
- Automatically scaling up resources in response to increased load.
- Rolling back deployments that are causing issues.
- Failing over to backup systems in case of failures.
Implement a “runbook automation” approach where documented procedures can automatically trigger well-defined actions in response to events. Data shows that automation can reduce incident response times by up to 50%, minimizing the impact of downtime.
Specifically regarding Event Queue backlog incidents, configure auto-scaling policies based on queue depth. When depth exceeds an acceptable threshold, proactively add consumers. Evaluate using Dead Letter Queues for poisoned messages to prevent indefinite processing loops.
Governance Model: Continuous Improvement and Learning
A robust governance model is essential for ensuring the long-term reliability and performance of your ROMI analytics integration. This model should encompass:
- Regular performance testing: Conduct load testing, stress testing, and chaos engineering exercises to identify and address potential bottlenecks and failure points.
- Proactive monitoring: Ensure that critical infrastructure, applications, and services are continually monitored. Set up alerts based on key metrics (e.g., response time, errors).
- Post-incident reviews: Conduct thorough post-incident reviews to identify root causes and implement preventative measures.
- Security audits: Regularly audit your systems for security vulnerabilities.
Data suggests that organizations that invest in regular testing and monitoring experience significantly fewer incidents and faster recovery times. Embrace a culture of continuous improvement and learning. Share incident reports and lessons learned across teams to promote knowledge sharing and prevent future incidents. Invest in CI/CD Optimization for 1C-Bitrix Partner Automation: Reducing Release Risk via Documentation Portal Redesign /blog/general/ci-cd-optimization-1c-bitrix-reliability-and-release-management-programs-documentation-portal-redesign-for-developer-onboarding-partner-network-automation-operating-model/ to streamline the deployment process and reduce the risk of errors.
Event Queue Backlog Recovery for E-commerce Analytics Pipelines
Address event queue backlog recovery for enhanced E-commerce ROMI analytics pipelines which necessitates a multi-faceted approach. Prioritize building visibility into queue depth, consumption rates, and message age. Establish alerting thresholds that trigger when metrics deviate from baseline expectations.
Implement message prioritization to handle the most urgent events first. Implement retry policies with exponential backoff. Consider utilizing Dead Letter Queues to isolate problematic or corrupt messages.
When a backlog occurs, scale the consumer pool to increase processing capacity. Partition the queue to operate concurrently. Implement checkpointing and idempotency to ensure messages aren't processed multiple times during restarts. A strategy such as this mirrors recommendations found in Webhook reliability: CTO-as-a-Service incident recovery with retry policy checklist /blog/general/webhook-reliability-cto-as-a-service-transformation-tracks-event-queue-backlog-recovery-after-incident-webhook-reliability-checklist-and-retry-policy/, adapting it to an E-commerce ROMI context.
Anti-Patterns in High-Availability Design
- Ignoring Data Privacy: Collecting and processing user data without proper consent or anonymization is a major anti-pattern.
- Single Point of Failure: Designing systems with a single point of failure can lead to service outages.
- Lack of Monitoring: Insufficient monitoring and alerting can make it difficult to detect and respond to incidents.
- Inadequate Testing: Skipping load testing and stress testing can result in unexpected performance issues during peak loads.
- Poor Incident Management: Lack of clearly defined incident response procedures can prolong downtime and increase the impact of incidents.
- Automated CRM/ERP data sync: AI moderation system migration handbook for stable legacy connector replacement /blog/general/automated-crm-erp-data-sync-ai-moderation-and-smart-routing-systems-migration-of-legacy-crm-erp-connectors-to-unified-api-layer-crm-erp-sync-reliability-handbook/ is another consideration. Improper syncing creates data inconsistencies, impacting ROMI accuracy.
Wrap-up: Embracing a Data-Driven Approach
Building high-availability microservices for e-commerce ROMI analytics demands a blend of architectural expertise, data privacy awareness, and operational excellence. By adopting a data-backed decision framework, quantifying risk appetite, implementing multi-region deployments, automating incident response, and embracing continuous improvement, you can create a system that delivers reliable insights while safeguarding user privacy. Investing in these high-availability measures improves system uptime and increases customer satisfaction, ultimately driving better business results.
Need help architecting a high-availability microservices solution tailored to your specific needs? Contact us today to learn more about our services.
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.