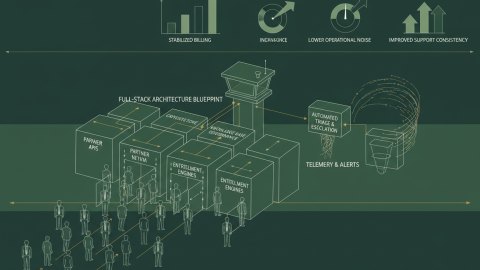
As a personal systems architect, I frequently encounter CTO-as-a-Service engagements struggling with disconnected knowledge bases and inconsistent support delivery. This directly impacts Return on Managed Investment (ROMI) and client satisfaction. The problem: Long approval cycles and enterprise constraints impede agile data governance. The solution? A strategically designed data quality monitoring system tailored for knowledge base governance and integrated into a standard, actionable delivery process audit.
This article details a benchmarking study I conducted across three client engagements, resulting in a practical data quality monitoring approach, complete with an audit template. The goal is to empower CTOs, CIOs, and support leaders to build trust and demonstrate ROI more effectively.
We will explore modeling data relationships, mapping risk propagation, enhancing visualization, and constructing a delivery process audit report template applicable within knowledge base governance. It serves as a starting point for internal quality assurance programs.
Graph-Based Modeling for Knowledge Base Consistency
Many organizations treat their knowledge base as a disorganized collection of articles. A graph-based approach links related concepts and reveals inconsistencies. We model our knowledge base around nodes and edges. Nodes represent concepts, FAQs, troubleshooting guides, or product features. Edges depict relationships between these nodes, such as 'is relevant to', 'resolves issue', or 'requires update when X changes'.
Checklist for Graph-Based Modeling:
- Identify key concepts within the knowledge base.
- Define the types of relationships that exist between concepts.
- Implement a graph database or utilize a graph library within your system (if technically feasible).
- Create a data governance plan that defines node and edge types, attributes, and validation rules.
Example:
Consider a 'Payment Processing' node. Edges connect this to nodes like 'Credit Card Validation', 'Transaction Limits', and 'Error Codes'. We can now trace errors in payment processing to specific gaps or inaccuracies in the linked nodes.
Entity Relationships: Mapping Data Dependencies
Beyond simple relationships, we need to understand the dependencies between data entities. A change in one entity often triggers updates in related entities. Incorrect propagation of these updates introduces data quality issues. These entities often include:
- Support Tickets: Customer issues and resolutions.
- Knowledge Base Articles: Documentation for products and troubleshooting.
- Product Specifications: Detailed information about product features.
- Training Materials: Guides for internal and external users.
We track the relationships between each of these entities. For instance, the resolution of a support ticket should ideally trigger an update to the relevant knowledge base article. During the benchmarking study, we measured the lag time between issue resolution and documentation updates. A significant lag indicates a potential data quality issue.
Geo Nodes for Localization and Regional Compliance
For global organizations, knowledge base content must often comply with regional regulations and cater to various language preferences. We represent different regions as geographic nodes connected to relevant content entities. For example, a 'GDPR Compliance' node in Europe will be linked to specific articles detailing data privacy regulations.
Implementation Details:
- Identify key geographic regions: Define the territories your organization serves.
- Map regulatory requirements: Document compliance standards for each region.
- Tag content by location: Categorize knowledge articles based on geographic relevance.
- Apply a periodic audit to review that all geo-specific material adheres to current regulations.
Risk Propagation: Identifying Data Quality Bottlenecks
Understanding how data quality issues propagate through the system is paramount. Using graph-based modeling and dependency mapping, we can identify potential bottlenecks. If an error exists in a fundamental node (e.g., a core product feature), it could spread rapidly to other areas, impacting support ticket resolutions, training materials, and even product specifications.
Steps for Identifying Risk Propagation:
- Conduct a failure mode and effects analysis (FMEA) on critical data entities.
- Simulate change propagation scenarios to assess the impact of errors.
- Prioritize mitigation efforts based on the severity and probability of risk.
This approach shifts data quality monitoring from a reactive exercise to a proactive risk management strategy.
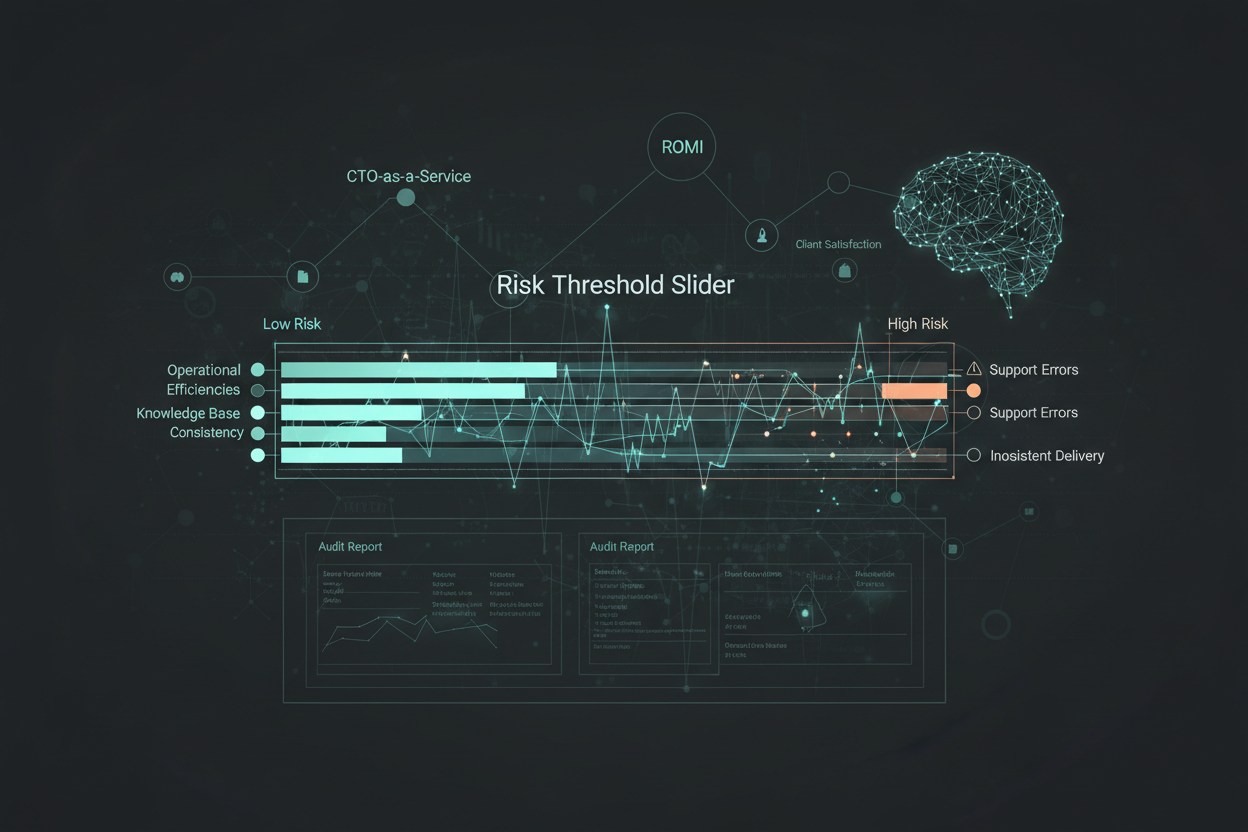
Visualization for Reporting and Remediation
Effective visualization transforms raw data into actionable insights. Leverage dashboards to track data quality metrics, visualize relationships between entities, and highlight areas of concern. Essential metrics include:
- Article Accuracy: Percentage of articles that are accurate and up-to-date.
- Article Coverage: Proportion of support tickets addressed by existing articles.
- Resolution Time: Average time taken to resolve support issues related to knowledge base gaps.
- Content Freshness: Average age of articles in the knowledge base (highlighting stale content).
Data visualizations must be self-explanatory and tailored to different stakeholders. Executive reports should focus on high-level business outcomes, while technical teams require detailed views for targeted remediation.
Delivery Process Audit Report Template for Enhanced ROMI
The culminating element is a delivery process audit report template that synthesizes the data quality monitoring findings into a structured document. This template serves as a communication tool between the technical team and leadership, tracking progress and demonstrating ROMI.
Template Structure:
- Executive Summary: Overview of key findings, impact on business goals, and recommendations.
- Data Quality Assessment: Detailed analysis of article accuracy, coverage, and resolution time metrics.
- Risk Propagation Analysis: Identification of potential bottlenecks and their impact.
- Action Plan: Specific steps to address data quality issues, along with timelines and responsibilities.
- Progress Tracking: Monitor progress against the action plan and provide regular updates.
This is an extract from a real-world project, if you need assistance in similar use-cases, please take a look at our services.
Common Anti-Patterns in Data Quality Monitoring
- Ignoring Contextual Relevance: Focus mainly on measuring all of data entities, forgetting the exact support flow.
- Treating All Data Equally: Prioritize what matters depending on tiering for customers.
- Data Overload: Too many metrics makes the report useless.
- Lack of Owner: Data collection without assigning clear responsibility creates a 'tragedy of the commons'.
Practical Implementation Steps
Turning a data quality monitoring model into reality requires a thoughtful execution plan. These steps need to be prioritized depending on the current maturity level of data management.
- Assess Current Knowledge Base: Audit existing content for gaps, inaccuracies, and outdated information.
- Automate Content Validation: Integrate automated checks into your content creation process.
- Define Clear Content Governance Policies: Establish standards for content creation, review, and updates.
- Establish Feedback Loops: Gather feedback from support agents and customers to identify areas for improvement.
- Iterative Refinement: Continuously monitor and refine your data quality monitoring system based on feedback and results.
Conclusion
In conclusion, data quality monitoring that is integrated into the fabric of a CTO-as-a-Service offering demonstrates concrete value to clients. The graph-based and risk-aware methodology described in this article, coupled with a robust delivery process audit template, drives efficiencies, enhances ROMI, and enables service consistency. This approach shifts data quality maintenance from being a reactive burden to a proactive advantage. For insight on related topics, see Tenant-Aware Observability or Checkout Optimization. For a deeper dive into automation, explore API release management automation
Related reads
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.