Development of SaaS Platform GeoIP + Antifraud API - geoip.space
Industry
Fintech, E-commerce, SaaS, Adtech
Period
Pricing from $10/month; up to $30/month; Enterprise customization
Role
Geo API + Antifraud Scoring
Tech stack
REST API (JSON), webhooks, SDK snippets for PHP/Node/Python/Go/Java
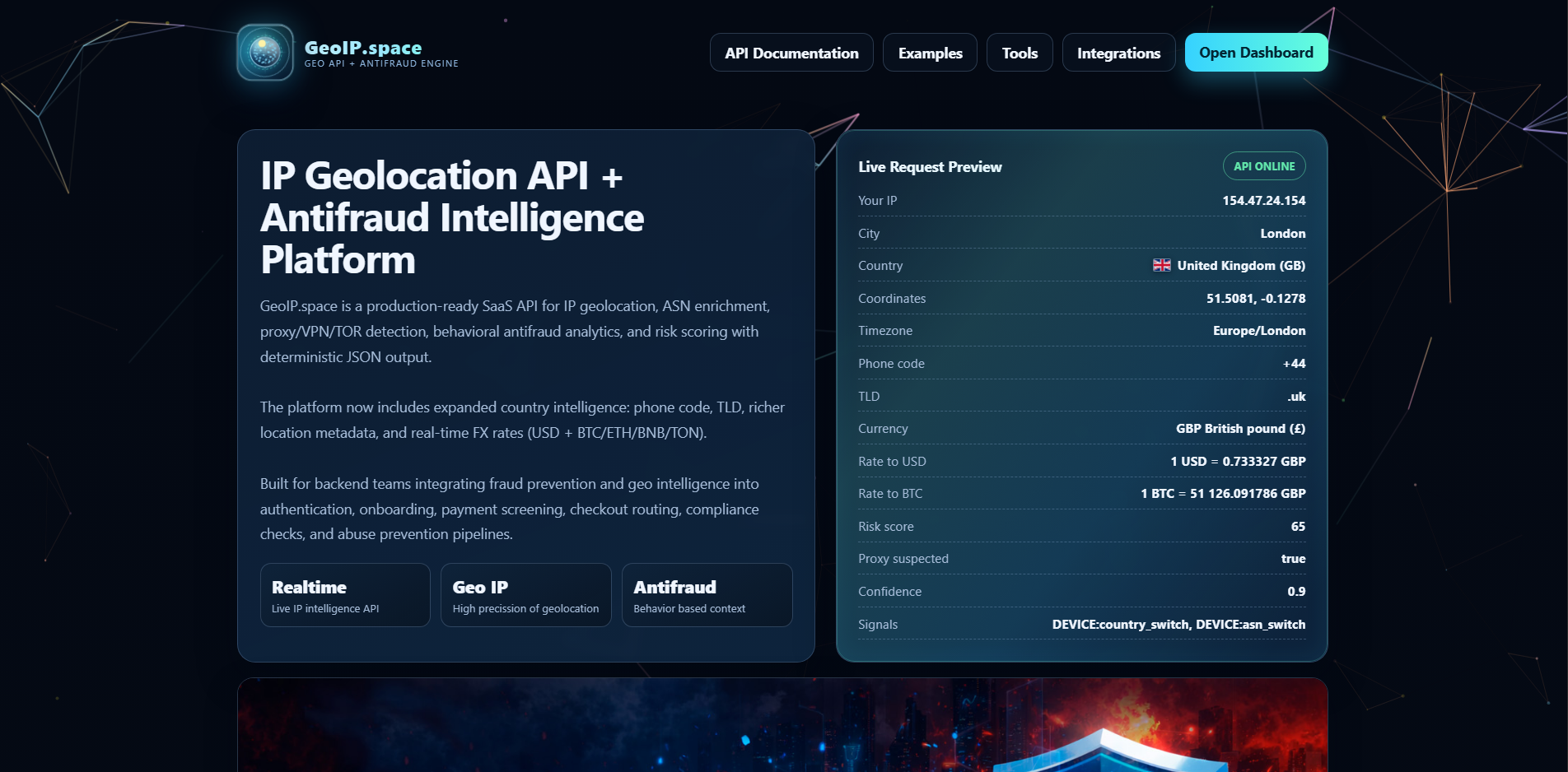
Problem
- Pricing based on number of checks and SLA.
- Separate limits for real-time and batch processing.
- Enterprise: dedicated environment and compliance package.
When I joined "Development of SaaS Platform GeoIP + Antifraud API - geoip.space", the pattern was familiar: local fixes existed, but there was no shared model connecting business goals to technical execution. That gap kept incidents recurring and manual overhead growing.
I decomposed the issue into controllable layers: input signals, decision rules, handoff points and post-release quality control. This immediately clarified where performance was being lost and why previous fixes did not hold.
Approach and solution
- Integration with any backend via REST.
- Webhook scenarios for SIEM/CRM/BI.
- Support for feature flags to enable safe rollout.
Instead of patching symptoms, I implemented a phased model: acceptance criteria first, minimum viable core second, and scale expansion only after stability was proven. This created measurable progress at each stage.
Operational governance was part of the implementation itself: ownership boundaries, deviation handling and explicit escalation logic. That made the outcome repeatable rather than person-dependent.
Architecture
REST API (JSON), webhooks, SDK snippets for PHP/Node/Python/Go/Java
Architecturally, the key principle was "observability before complexity". It allowed the team to see real impact of each change and keep control while scaling.
The stack (REST API (JSON), webhooks, SDK snippets for PHP/Node/Python/Go/Java) was treated as an enabler, not a goal: every decision was evaluated by impact on delivery speed, stability and support cost.
Outcome
Optimized for authentication, onboarding, payout, and order-risk workflows where decision speed and traceability of causes are critical.
Business impact was not limited to isolated metric gains. The team received a practical operating model with clearer priorities, faster decisions and lower regression risk.
I documented outcomes in a before/after format tied to practical KPIs, so leadership could directly map engineering work to commercial value.
Metrics
- Reduction in manual verification.
- Decreased response time of the risk engine.
- Improved accuracy in traffic segmentation.
- Team response speed to deviations and incidents.
- Manual overhead share before vs after rollout.
- Stability of critical user flow under load.
- Release predictability and regression frequency.
- Input quality: less noise, higher useful outcome.
Deliverables
- API keys and environments.
- Scoring rules and webhook schemas.
- Monitoring package and runbook.
- Target architecture map with implementation priorities.
- Phased rollout plan with acceptance criteria.
- Operational runbook and escalation model.
- Post-release quality checklists.
- 30/60-day optimization backlog.
Unique solution in this case
In this case, the differentiator was risk-aware traffic filtering with explainable decision rules. The delivery was not a one-off patch: architecture constraints were fixed first, then a production workflow was rolled out so the team can scale without losing control.
Comparison: before vs after systems rollout
| Aspect | Before | After |
|---|---|---|
| Delivery model | Local fixes without unified architecture | Systems-first rollout with clear architecture logic |
| Operational control | Manual and context-dependent execution | Transparent rules, checklists and quality control |
| Business impact | Pricing based on number of checks and SLA. Separate limits for real-time and batch processing. Enterprise: dedicated environment and compliance package. | Reduces fraud losses and false-positive blocks through explainable risk scoring. |
How-to: how to replicate this result in your project
- Define business objective and success metric before implementation.
- Map current flow and identify losses in data, time and quality.
- Scope minimum viable rollout with explicit acceptance criteria.
- Launch phased rollout with observability and trace logging.
- Lock support, escalation and iteration workflow.
Practical implementation checklist
- Baseline metrics captured before rollout.
- Integration points and data contracts verified.
- Failure modes and fallback scenarios tested.
- Post-launch quality controls enabled.
- Operational runbook prepared for the team.
- 30/60-day optimization plan documented.
Related services, offers and products
Need a similar case delivered?
Describe your task and I will suggest architecture, scope and delivery format.