Many B2B corporate sales websites rely on partner networks to expand their reach and drive revenue. A critical piece of this puzzle is the accurate and timely reconciliation of payment statuses. However, integrating with various partners often means dealing with a heterogeneous landscape of webhook providers, leading to inconsistencies, delays, and ultimately, a lack of trust.
Imagine a scenario where a customer makes a purchase through a partner's website. The partner's system is supposed to send a webhook notification upon successful payment. However, due to network issues, coding errors on the partner side, or variations in webhook payload formats, the notification might be delayed, incomplete, or even missing altogether. This creates discrepancies between the data in your system and the partner's system, leading to support tickets, frustrated customers, and strained partner relationships. Predictable API policies supported by robust reconciliation are key for high throughput in cross-functional delivery teams.
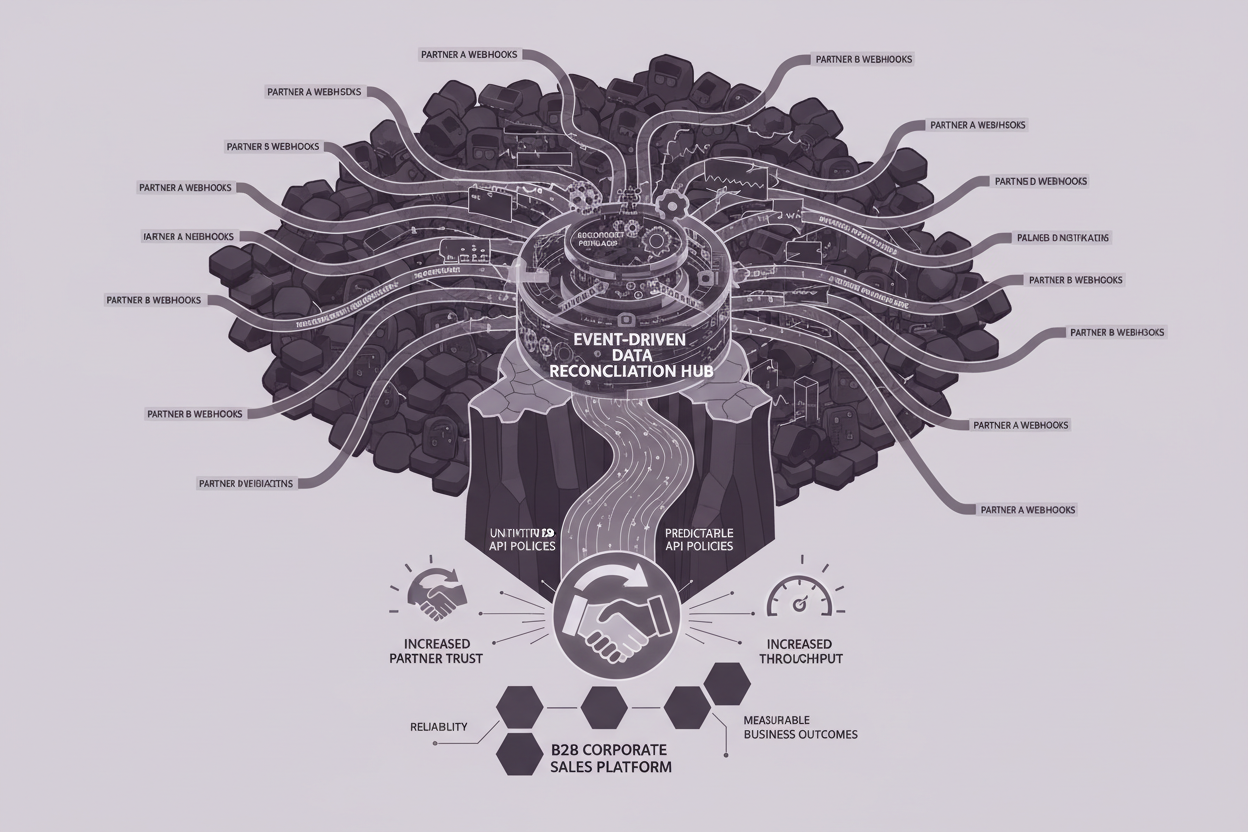
Use Case Spotlight: High-Volume Corporate Sales Platform
A large corporate sales website experiences high volumes of transactions through its partner network. Integration with various partner systems is achieved via webhooks. However, due to the diverse nature of these partner systems, the corporate website faces significant challenges in maintaining data consistency and ensuring accurate payment status reporting. This leads to:
- Delayed order fulfillment
- Increased customer support inquiries
- Partner dissatisfaction due to discrepancies in reported commissions.
The company aims to implement a robust event-driven data reconciliation mechanism to address these issues and improve overall operational efficiency.
Risk Indicators: Identifying Potential Reconciliation Issues
Before diving into the implementation details, it's crucial to identify the key risk indicators that signal the need for data reconciliation. Here's a checklist:
- High discrepancy rates: An unusually high number of mismatches between your system's payment status and the partner's. Establish a baseline discrepancy rate and set alerts when it exceeds a certain threshold.
- Delayed notifications: Webhook notifications arriving significantly later than expected. Monitor the latency of incoming webhooks and flag those that exceed a predefined SLA.
- Incomplete data: Missing or invalid data fields in webhook payloads. Implement validation checks on incoming webhooks and reject those with missing or invalid data.
- Increased support tickets: A surge in customer or partner inquiries related to order status or payment discrepancies. Track the volume of support tickets and analyze the underlying causes.
- Failed audit checks: Inconsistencies detected during internal or external audits related to financial reporting or compliance.
Failing to address these risk indicators can result in financial losses, reputational damage, and erosion of partner trust.
Designing the Event-Driven Data Flow
The core of our solution is an event-driven architecture that enables asynchronous processing of payment-related events. Here's a step-by-step breakdown of the data flow:
- Payment Event Capture: When a payment event occurs (e.g., payment initiated, payment successful, payment failed) in a partner's system, a webhook notification is sent to your platform.
- Event Ingestion and Validation: An API endpoint receives the webhook notification. The endpoint performs initial validation checks to ensure the payload is well-formed and contains the necessary data fields. Invalid events are rejected and logged for further investigation.
- Message Queue: Validated events are published to a message queue (e.g., Kafka, RabbitMQ). This decouples the event producer (the API endpoint) from the event consumers (the reconciliation processes).
- Reconciliation Processor: A dedicated reconciliation processor subscribes to the message queue and consumes payment events. This processor is responsible for comparing the data in the event with the data in your system.
- Data Reconciliation Logic: The reconciliation processor executes a series of checks and transformations to reconcile the data. This might involve mapping partner-specific field names to your internal data model, handling currency conversions, or applying business rules to determine the final payment status.
- Discrepancy Resolution: If discrepancies are detected, the reconciliation processor attempts to resolve them automatically. This could involve updating your system with the correct payment status, triggering a retry mechanism, or sending an alert to a support team.
- Auditing and Logging: All events, reconciliation results, and discrepancy resolutions are logged for auditing and reporting purposes.
Implementation Example: Handling Non-Uniform Payloads
A common challenge is dealing with non-uniform webhook payloads from different partners. To address this, we can use a mapping service that transforms incoming payloads into a standardized format.
# Example Python code for a payload mapping service
import json
def map_payload(partner_id, payload):
# Load the mapping configuration for the specific partner
mapping_config = load_mapping_config(partner_id)
# Transform the payload using the mapping configuration
standardized_payload = {}
for source_field, target_field in mapping_config.items():
standardized_payload[target_field] = payload.get(source_field)
return standardized_payload
def load_mapping_config(partner_id):
# Placeholder for loading mapping configuration from a database or file
# This should be replaced with a real implementation
if partner_id == "partner_a":
return {
"payment_id": "payment_reference",
"amount": "payment_amount",
"status_code": "payment_status"
}
elif partner_id == "partner_b":
return {
"transaction_id": "payment_reference",
"value": "payment_amount",
"payment_state": "payment_status"
}
else:
raise ValueError(f"No mapping configuration found for partner ID: {partner_id}")
# Example usage
payload_partner_a = {
"payment_id": "12345",
"amount": 100.00,
"status_code": "success"
}
standardized_payload = map_payload("partner_a", payload_partner_a)
print(standardized_payload)
# Expected output: {'payment_reference': '12345', 'payment_amount': 100.0, 'payment_status': 'success'}
This demonstrates a simple mapping service that takes a partner ID and a payload as input and returns a standardized payload. The `load_mapping_config` function retrieves the mapping configuration for the specific partner from a database or file. For additional context, refer to Checkout Optimization Experiment Map.
Deployment Steps: Implementing the Reconciliation Pipeline
Here's a step-by-step guide to deploying the event-driven data reconciliation pipeline:
- Set up the Message Queue: Choose a message queue solution (e.g., Kafka, RabbitMQ) and configure it for high availability and fault tolerance.
- Develop the API Endpoint: Create an API endpoint that receives webhook notifications from partners. Implement validation checks to ensure the payloads are well-formed.
- Implement the Reconciliation Processor: Develop the reconciliation processor that subscribes to the message queue and consumes payment events. Implement the data reconciliation logic, including payload mapping, data transformation, and business rule execution.
- Configure Discrepancy Resolution: Implement mechanisms for automatically resolving discrepancies. This might involve updating your system with the correct payment status, triggering a retry mechanism, or sending an alert to a support team.
- Deploy Auditing and Logging: Configure comprehensive auditing and logging to track all events, reconciliation results, and discrepancy resolutions.
- Implement Alerting: Set up alerting mechanisms to notify support teams when discrepancies are detected or when critical thresholds are breached.
- Test and Deploy: Thoroughly test the reconciliation pipeline in a staging environment before deploying it to production. Then, see API release management automation checklist before you push the production go-live button.
Observability: Monitoring the Health of the Reconciliation Process
Once the reconciliation pipeline is deployed, it's crucial to monitor its health and performance. Implement the following observability measures:
- Real-time dashboards: Create real-time dashboards that visualize key metrics, such as the number of events processed, the discrepancy rate, the resolution time, and the overall health of the pipeline.
- Log aggregation: Aggregate logs from all components of the pipeline into a central logging system. This allows you to quickly identify and troubleshoot issues.
- Distributed tracing: Implement distributed tracing to track events as they flow through the pipeline. This helps you identify bottlenecks and performance issues.
- Alerting: Set up alerting mechanisms to notify support teams when critical thresholds are breached. For inspiration, High-load SLA target hardening is key.
Key Metrics to Track
- Event processing rate: The number of payment events processed per unit of time.
- Discrepancy rate: The percentage of events that result in discrepancies.
- Resolution time: The time it takes to resolve a discrepancy.
- Pipeline latency: The time it takes for an event to flow through the entire pipeline.
- Error rate: The percentage of events that result in errors.
Next Steps
Properly implemented event-driven systems for B2B data reconciliation improve data quality, reduce operational overhead, and builds stronger partner relationships. By continuously monitoring the health of your systems you can make smart decisions to optimize your platform and ultimately provide better service to your customers.
Do you need help designing and implementing a robust event-driven architecture for your B2B sales platform? Contact us today to discuss your specific challenges and how we can help you achieve your business goals.
Related reads
Anti-Patterns to Avoid
When designing and implementing an event-driven data reconciliation system, be aware of these common anti-patterns that can negatively impact performance, reliability, and maintainability:
- Tight Coupling: Avoid tight coupling between services. Each service should be independent and communicate through events. Don't encode business logic directly within the webhook endpoints, as this reduces flexibility and increases the risk of cascading failures.
- Ignoring Idempotency: Ensure your reconciliation processor is idempotent. It should be able to process the same event multiple times without causing unintended side effects. This is especially important when dealing with unreliable networks or message queue failures.
- Lack of Monitoring: Failing to implement comprehensive monitoring and alerting can lead to undetected issues and prolonged outages. Track key metrics and set up alerts for critical thresholds.
- Insufficient Data Validation: Inadequate data validation can lead to data corruption and reconciliation errors. Validate all incoming data and implement proper error handling.
- Over-reliance on Manual Resolution: While some discrepancies may require manual intervention, strive to automate the reconciliation process as much as possible. A large volume of manual resolutions indicates a problem with your system design or data quality: consider creating an admin-level panel with well-defined escalation rules.
Advanced Reconciliation Strategies
Beyond basic data matching, consider these advanced strategies to improve the accuracy and efficiency of your reconciliation process:
- Fuzzy Matching: Implement fuzzy matching algorithms to account for minor variations in data, such as typos or inconsistencies in formatting.
- Time-Based Reconciliation: Reconcile data based on timestamps, allowing you to identify and resolve discrepancies caused by delays in event processing. Consider windowed aggregations.
- Exception Handling: Implement a robust exception handling mechanism to gracefully handle errors and prevent them from stopping the reconciliation process. Log all exceptions and set up alerts for critical errors.
- Dead Letter Queues: Configure dead letter queues to store events that cannot be processed. This allows you to investigate and resolve the underlying issues without losing valuable data, especially important during partner onboarding when schema drift is expected.
Practical Checklist for Reconciliation Pipeline Implementation
Use this checklist to guide your implementation of the data reconciliation pipeline:
- Define Reconciliation Objectives: Clearly define the objectives of the reconciliation process. What data needs to be reconciled? What are the acceptable error rates? What are the business impacts of discrepancies?
- Identify Data Sources: Identify all data sources that need to be included in the reconciliation process.
- Define Data Mapping: Define a clear mapping between the fields in each data source.
- Implement Data Transformation: Implement data transformation logic to ensure that the data is consistent across all sources. This should cover string formatting, number precision, and enum value mappings.
- Implement Reconciliation Logic: Implement the reconciliation logic, including data matching, discrepancy detection, and resolution.
- Implement Error Handling: Implement error handling and exception handling mechanisms.
- Implement Auditing and Logging: Implement comprehensive auditing and logging.
- Implement Monitoring and Alerting: Implement monitoring and alerting.
- Test and Validate: Thoroughly test and validate the reconciliation pipeline, including unit testing, integration testing, and user acceptance testing.
- Document: Document all aspects of the reconciliation process, including the architecture, design, implementation, and testing. Document data ownership.
Optimizing Performance and Scalability
Consider these strategies to optimize the performance and scalability of your reconciliation pipeline:
- Asynchronous Processing: Process events asynchronously using message queues to avoid blocking the API endpoint and improve performance.
- Parallel Processing: Process events in parallel using multiple threads or processes to increase throughput. Partitioning keys in message queue design enable effective parallelism.
- Caching: Cache frequently accessed data to reduce database load and improve response times.
- Database Optimization: Optimize your database queries and indexes to improve performance. Don't query data that is not absolutely needed.
- Horizontal Scaling: Design your pipeline to be horizontally scalable, allowing you to add more resources as needed to handle increasing volumes of data.
Security Considerations
Security is paramount when dealing with payment data. Implement the following security measures:
- Data Encryption: Encrypt sensitive data at rest and in transit.
- Access Control: Implement strict access control policies to limit access to sensitive data.
- Authentication and Authorization: Implement strong authentication and authorization mechanisms to prevent unauthorized access to the pipeline.
- Regular Security Audits: Conduct regular security audits to identify and address vulnerabilities.
- Compliance: Ensure that your reconciliation pipeline complies with all relevant security and privacy regulations.
Example: Handling Delayed Notifications
Delayed notifications are a common problem in distributed systems. Here's an example of how to handle delayed payment status updates:
- Implement a Retry Mechanism: If a payment event is not received within a certain timeframe, implement a retry mechanism to request the payment status from the partner again.
- Use a Time-Based Reconciliation Window: Define a time-based reconciliation window. Payments that are not reconciled within this window are flagged for manual review.
- Utilize Sequence Numbers: If the partner provides sequence numbers for events, use them to detect missing or out-of-order events.
By incorporating these strategies, you can build a robust and reliable data reconciliation system that ensures accurate payment statuses, strengthens partner relationships, and improves overall business performance.
Relevant offers
If this article matches your task, here are two offers you can use to move from insight to implementation without extra discovery.
Personal account module on 1C-Bitrix
I build a Bitrix personal account around your business logic: requests, documents, statuses, notifications and access control.
Web application architecture audit
Audit architecture, security and performance with a clear improvement plan.